centos配置kdump捕获内核崩溃
一、什么是kdump
kdump 是一种先进的基于 kexec 的内核崩溃转储机制。当系统崩溃时,kdump 使用 kexec 启动到第二个内核。第二个内核通常叫做捕获内核,以很小内存启动以捕获转储镜像。第一个内核保留了内存的一部分给第二内核启动用。由于 kdump 利用 kexec 启动捕获内核,绕过了 BIOS,所以第一个内核的内存得以保留。这是内核崩溃转储的本质。
kdump 需要两个不同目的的内核,生产内核和捕获内核。生产内核是捕获内核服务的对像。捕获内核会在生产内核崩溃时启动起来,与相应的 ramdisk 一起组建一个微环境,用以对生产内核下的内存进行收集和转存。
二、kdump执行流程
为了更容易理解这里我以三张图展示下kdump的执行流程,首先看的是Vivek Goyal 的PPT中两幅图
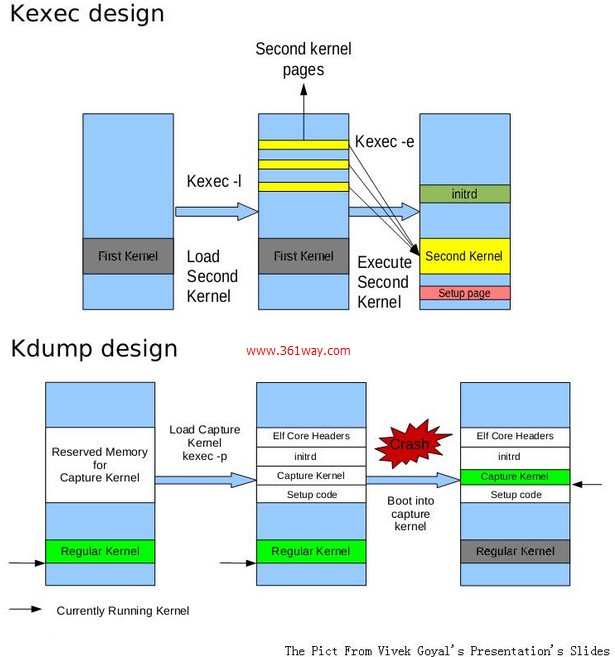
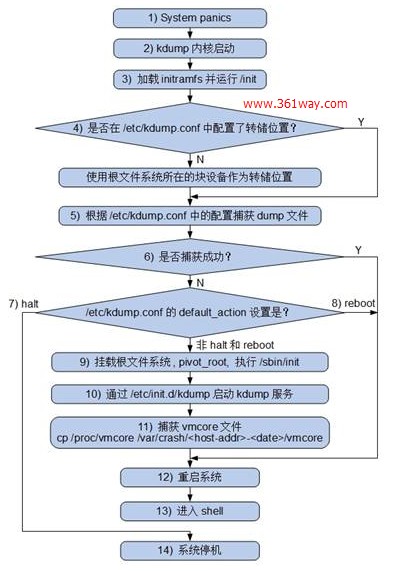
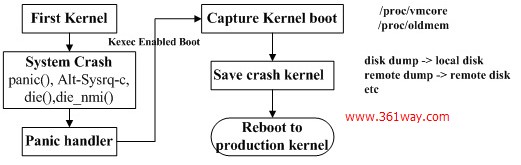
下面两副图是来自于IBM技术论坛上的rhel6.2和suse11下的执行流程图
rhel6.2的执行流程
suse11下的执行流程
三、kdump 的安装及测试
1、相关包的安装
这里以centos6.x下的安装为例
1kexec-tools
2kexec package
3kernel-debuginfo //需单独另外安装,yum源里没有
4crash analysis package
5安装命令如下
6# yum -y install kernel kexec-tools
如果需要图形化的配置工具,还要安装system-config-kdump包。
2、grub内核配置
编辑 /boot/grub/grub.conf 配置文件,修改用到的引导部分,加入crashkernel部分,
参数格式是:
1crashkernel=nn[KMG]@ss[KMG]
2nn表示要为crashkernel预留多少内存
3ss表示为crashkernel预留内存的起始位置
示例如下:
1root (hd0,0)
2kernel /vmlinuz-2.6.18-92.el5 ro root=LABEL=/ crashkernel=256M@16M
3initrd /initrd-2.6.18-92.el5.img
4或
5root (hd0,0)
6kernel /vmlinuz-2.6.32-431.17.1.el6.x86_64 ro root=/dev/mapper/vg_centos-lv_root rd_NO_LUKS LANG=en_US.UTF-8 rd_LVM_LV=vg_centos/lv_swap rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=128M@48M rd_LVM_LV=vg_centos/lv_root KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet
7initrd /initramfs-2.6.32-431.17.1.el6.x86_64.img
修改完成并重启后,可以通过cat /proc/cmdline 查看kernel 启动配置选项 ,此处修改重启后我的/proc/cmdline文件为:
ro root=/dev/mapper/vg_centos-lv_root rd_NO_LUKS LANG=en_US.UTF-8 rd_LVM_LV=vg_centos/lv_swap rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=128M@48M rd_LVM_LV=vg_centos/lv_root KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet
注:在centos 7.x上,开始使用grub2 引导,配置路径文件为
1UEFI引导时
2/boot/efi/EFI/centos/grub.cfg
3BIOS引导时
4/boot/grub2/grub.cfg
小技巧:修改该值可以直接使用grubby命令进行修改grub.cfg文件(该命令同样适用于grub2和UEFI引导的情况)如:
1[root@localhost boot]# grubby --update-kernel=DEFAULT --args=crashkernel=128M
3、启动kdump服务
在centos6.x上可以使用下面的命令启动kdump服务(在suse11企业版中,kdump服务名为boot.kdump)
1# /etc/init.d/kdump start
2Starting kdump: [FAILED]
发现启动失败,通过查看/var/log/message日志,可以发现如下内容:kdump: No crashkernel parameter specified for running kernel
a、这里我尝试过grub.cfg里配置crashkernel=auto 、crashkernel=128M@16M,启动失败,后来看到oracle 站点上的示例,改为crashkernl=128M@48M后,发现kdump服务可以启动成功,而且每次修改后都需要reboot重启系统,后来查了下手动指定@xxxM的时候可能会失败的原因,是因为如果第二个内核与第一个内核在地址空间上有重叠的话,会导致第二个内核启动失败,所以此处可以直接设置为crashkernel=128M。
b、crashkernle 的值也要根据具体自己的实际物理内存大小灵活调整,如实际物理内存实在足够大,可以设置为256M、512M 。
c、crashkernel 的值设置后,使用free -m 要看时,会发现内存少了@ 号前面配置的值大小。如,我配置的是crashkernel@128M@48M,就会少128M内存。
再次启动kdump服务
1[root@361way sysconfig]# /etc/init.d/kdump restart
2Stopping kdump: [ OK ]
3No kdump initial ramdisk found. [WARNING]
4Rebuilding /boot/initrd-2.6.32-431.17.1.el6.x86_64kdump.img
5Starting kdump: [ OK ]
会发现会在/boot 目录下新增一个以kdump结尾的内核文件。
1[root@361way boot]# ls
2config-2.6.32-431.17.1.el6.x86_64 grub lost+found System.map-2.6.32-431.17.1.el6.x86_64
3config-2.6.32-431.el6.x86_64 initramfs-2.6.32-431.17.1.el6.x86_64.img memtest86+-4.10 System.map-2.6.32-431.el6.x86_64
4efi initramfs-2.6.32-431.el6.x86_64.img symvers-2.6.32-431.17.1.el6.x86_64.gz vmlinuz-2.6.32-431.17.1.el6.x86_64
5elf-memtest86+-4.10 initrd-2.6.32-431.17.1.el6.x86_64kdump.img symvers-2.6.32-431.el6.x86_64.gz vmlinuz-2.6.32-431.el6.x86_64
注:在centos 7.x 上开始使用systemd进行服务进程的启动管理,启动服务折方法需要通过以下方法执行
1# systemctl enable kdump.service //配置服务的开机自启动
2# systemctl start kdump.service //启动kdump服务
4、测试模拟kdump
配置完成后,需要重启机器加载新的内核。可以使用下面的方法默认kdmp生成
1# service kdump on //设置服务开机自启动
2# reboot //重启系统使刚刚所有的修改生效
3# sync
4# echo c > /proc/sysrq-trigger
执行后,机器会重启,重启进入系统后,会在/var/crash 目录生成kdmp文件,文件内容可以通过crash命令进行分析,后面会对此进行专门的介绍。
四、kdump的高级配置
和kdump相关的配置文件有两个:一个是/etc/sysconfig/kdump,该文件内的内容一般无需修改 -- 网上一些技术站上在kdump服务启动不成功时修改这里,这里提示下,如果是通过yum源正常安装的,该文件无需修改;一个是/etc/kdump.conf 。这里指的高级配置主机是/etc/kdump.conf ,该配置文件的可配置选项可通过man 5 kdump.conf 获取帮助,这里只列举下常用到的部分:
1、设置kdump文件成生的位置
控制路径的主要有两部分:
1#raw /dev/sda5
2#ext4 /dev/sda3
3#ext4 LABEL=/boot
4#ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937
5#nfs my.server.com:/export/tmp
6#ssh [email protected]
7path /var/crash
前面的部分用于设置存储的设备或分区位置--可以是raw裸设备、本地分区、网络路径在本地的挂载点或通过ssh传输,path则是相对的存储路径。如我们通过nfs 将远程的一个分区挂载到本地的/mnt分区下,kdump文件就存储在/mnt/var/crash/下。默认上面的部分不设置就是相对根分区的相对路径,即/var/crash 。
需要特别指出的是,如果使用ssh进行传输,需要配置key认证,使用/etc/init.d/kdump propagate即可配置ssh认证传输,如下:
1kdump.conf中指定ssh网络传输
2ssh [email protected]/data/
3执行下面的命令会配置本机到192.168.0.100主机的key认证传输
4# service kdump propagate
5Generating new ssh keys… done.
6The authenticity of host '192.168.0.100 (192.168.0.100)' can't be established.
7RSA key fingerprint is 31:c2:d8:b6:eb:2e:03:64:cd:ba:56:e9:49:6e:5d:6c.
8Are you sure you want to continue connecting (yes/no)? yes
9Warning: Permanently added '192.168.0.100' (RSA) to the list of known hosts.
10[email protected]'s password:
11/root/.ssh/kdump_id_rsa.pub has been added to ~root/.ssh/authorized_keys2 on
12192.168.0.100
按照上面的配置,当有kdump生成时,会通过scp传输存储在192.168.0.100主机的/data/var/crash 目录下。
2、core_collector控制
该处是信息收集大小的关键,主要用到makedumpfile命令,centos 上的默认配置如下:
1core_collector makedumpfile -c --message-level 1 -d 31
-c 表示启动zlib进行数据压缩
–message-level 指定了信息收集的级别,1为只打印process indicator 日志信息,默认值为7,具体见下表
1Message | progress common error debug report
2Level | indicator message message message message
3---------+------------------------------------------------------
4 0 |
5 1 | X
6 2 | X
7 4 | X
8 * 7 | X X X
9 8 | X
10 16 | X
11 31 | X X X X X
-d 指定了kdump的过滤级别,具体见下表
1 | cache cache
2 Dump | zero without with user free
3 Level | page private private data page
4-------+---------------------------------------
5 0 |
6 1 | X
7 2 | X
8 4 | X X
9 8 | X
10 16 | X
11 31 | X X X X X
31表示过滤掉以上五种全部信息,这样kdump生成的速度就会更快,生成的vmcore文件也会较小。如果此处使用值0 ,表示不过滤任何信息,在kdump生成时,会记录主机当前的所有信息。这就是为什么在kdump生成时,有些主机只有几十M大小生成,有些主机确有几十 G大小的原因。更多用法可以查看makedumpfile命令的帮助文档。
3、指定default配置
该处的配置,我也参考了网上的一些配置,一些技术文档上使用的是defult reboot选项,而默认的是defult shell ,两者之间的区别是:
reboot: If the default action is reboot simply reboot the system and loose the core that you are trying to retrieve.
shell: If the default action is shell, then drop to an hush session inside the initramfs from where you can try to record the core manually.Exiting this shell reboots the system.
在查看/usr/share/doc/kexec-tools-2.0.0/kexec-kdump-howto.txt帮助手册中的解释更容易理解一些,如下:
1reboot --> reboot the system.
2shell --> drop to a shell with-in initrd. A user can try to capture the
3 vmcore manually.
从这个解释可以看到选择shell 可以手工的DIY一些东西,而选择reboot 会在kdump生成后简单直接的reboot 系统。除了上在两个选项,还会poweroff 、halt 可选,如果不是技术研究的目录,在生产环境上我想谁不会选择kdump生成后让系统挂起吧。
除上面三处之外,还有其他配置部分,如debug_mem 的配置等。具体可以看kdump.conf 的man 结果。
五、crash进行结果分析
crash包需要yum -y install crash 单独安装过,另外crash 命令需要依赖kernel-debuginfo 包(该包又依赖kernel-debuginfo-common包),该包的下载地址:http://debuginfo.centos.org/6/x86_64/ 。下载前先要确认下自己主机的内核版本。我在测试机上是通过下面的命令执行的:
1# uname -r
22.6.32-431.17.1.el6.x86_64
3# wget http://debuginfo.centos.org/6/x86_64/kernel-debuginfo-common-x86_64-2.6.32-431.17.1.el6.x86_64.rpm
4# wget http://debuginfo.centos.org/6/x86_64/kernel-debuginfo-2.6.32-431.17.1.el6.x86_64.rpm
下载完成后,通过rpm -ivh将这两个包安装。然后通过下面的命令进行crash分析
1# pwd
2/var/crash/127.0.0.1-2014-09-16-14:35:49
3# crash /usr/lib/debug/lib/modules/2.6.32-431.17.1.el6.x86_64/vmlinux vmcore
4crash 6.1.0-5.el6
5Copyright (C) 2002-2012 Red Hat, Inc.
6Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation
7Copyright (C) 1999-2006 Hewlett-Packard Co
8Copyright (C) 2005, 2006, 2011, 2012 Fujitsu Limited
9Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
10Copyright (C) 2005, 2011 NEC Corporation
11Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
12Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
13This program is free software, covered by the GNU General Public License,
14and you are welcome to change it and/or distribute copies of it under
15certain conditions. Enter "help copying" to see the conditions.
16This program has absolutely no warranty. Enter "help warranty" for details.
17GNU gdb (GDB) 7.3.1
18Copyright (C) 2011 Free Software Foundation, Inc.
19License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
20This is free software: you are free to change and redistribute it.
21There is NO WARRANTY, to the extent permitted by law. Type "show copying"
22and "show warranty" for details.
23This GDB was configured as "x86_64-unknown-linux-gnu"...
24 KERNEL: /usr/lib/debug/lib/modules/2.6.32-431.17.1.el6.x86_64/vmlinux
25 DUMPFILE: vmcore [PARTIAL DUMP]
26 CPUS: 1
27 DATE: Tue Sep 16 22:35:49 2014
28 UPTIME: 00:05:33
29LOAD AVERAGE: 0.00, 0.00, 0.00
30 TASKS: 175
31 NODENAME: localhost.localdomain
32 RELEASE: 2.6.32-431.17.1.el6.x86_64
33 VERSION: #1 SMP Wed May 7 23:32:49 UTC 2014
34 MACHINE: x86_64 (3398 Mhz)
35 MEMORY: 1 GB
36 PANIC: "Oops: 0002 [#1] SMP " (check log for details)
37 PID: 1412
38 COMMAND: "bash"
39 TASK: ffff88003d0b2040 [THREAD_INFO: ffff88003c33c000]
40 CPU: 0
41 STATE: TASK_RUNNING (PANIC)
42crash> bt
43PID: 1412 TASK: ffff88003d0b2040 CPU: 0 COMMAND: "bash"
44 #0 [ffff88003c33d9e0] machine_kexec at ffffffff81038f3b
45 #1 [ffff88003c33da40] crash_kexec at ffffffff810c59f2
46 #2 [ffff88003c33db10] oops_end at ffffffff8152b7f0
47 #3 [ffff88003c33db40] no_context at ffffffff8104a00b
48 #4 [ffff88003c33db90] __bad_area_nosemaphore at ffffffff8104a295
49 #5 [ffff88003c33dbe0] bad_area at ffffffff8104a3be
50 #6 [ffff88003c33dc10] __do_page_fault at ffffffff8104ab6f
51 #7 [ffff88003c33dd30] do_page_fault at ffffffff8152d73e
52 #8 [ffff88003c33dd60] page_fault at ffffffff8152aaf5
53 [exception RIP: sysrq_handle_crash+22]
54 RIP: ffffffff8134b516 RSP: ffff88003c33de18 RFLAGS: 00010096
55 RAX: 0000000000000010 RBX: 0000000000000063 RCX: 0000000000000000
56 RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000063
57 RBP: ffff88003c33de18 R8: 0000000000000000 R9: ffffffff81645da0
58 R10: 0000000000000001 R11: 0000000000000000 R12: 0000000000000000
59 R13: ffffffff81b01a40 R14: 0000000000000286 R15: 0000000000000004
60 ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
61 #9 [ffff88003c33de20] __handle_sysrq at ffffffff8134b7d2
62#10 [ffff88003c33de70] write_sysrq_trigger at ffffffff8134b88e
63#11 [ffff88003c33dea0] proc_reg_write at ffffffff811f2f1e
64#12 [ffff88003c33def0] vfs_write at ffffffff81188c38
65#13 [ffff88003c33df30] sys_write at ffffffff81189531
66#14 [ffff88003c33df80] system_call_fastpath at ffffffff8100b072
67 RIP: 00000036e3adb7a0 RSP: 00007fff22936c10 RFLAGS: 00010206
68 RAX: 0000000000000001 RBX: ffffffff8100b072 RCX: 0000000000000400
69 RDX: 0000000000000002 RSI: 00007fab7908b000 RDI: 0000000000000001
70 RBP: 00007fab7908b000 R8: 000000000000000a R9: 00007fab79084700
71 R10: 00000000ffffffff R11: 0000000000000246 R12: 0000000000000002
72 R13: 00000036e3d8e780 R14: 0000000000000002 R15: 00000036e3d8e780
73 ORIG_RAX: 0000000000000001 CS: 0033 SS: 002b
74crash>
上面,只是简单的通过打印堆栈信息,显示主机在出现kdump生成时,pid 为1412的bash进程操作。从上面的显示信息中也简单的看到有 write_sysrq_trigger 函数触发。crash在定位问题原因时,为我们提供了下面的命令:
1crash> ?
2* files mach repeat timer
3alias foreach mod runq tree
4ascii fuser mount search union
5bt gdb net set vm
6btop help p sig vtop
7dev ipcs ps struct waitq
8dis irq pte swap whatis
9eval kmem ptob sym wr
10exit list ptov sys q
11extend log rd task
12crash version: 6.1.0-5.el6 gdb version: 7.3.1
13For help on any command above, enter "help <command>".
14For help on input options, enter "help input".
15For help on output options, enter "help output".
由于crash的内容也较多,以下是针对suse下信息提到的一个脚本:
1mkdir -p /tmp/kdump
2crash $* <<EOF >/tmp/kdump/kdumpoutput.txt 2>&1
3log >/tmp/kdump/log.txt
4sys >/tmp/kdump/sys.txt
5bt >/tmp/kdump/bt.tx
6foreach bt >/tmp/kdump/all-bt.txt
7foreach files>/tmp/kdump/all-files.txt
8ps >/tmp/kdump/ps.txt
9swap>/tmp/kdump/swap.txt
10runq >/tmp/kdump/runq.txt
11mount >/tmp/kdump/mount.txt
12net >/tmp/kdump/net.txt
13dev >/tmp/kdump/dev.txt
14dev -i >/tmp/kdump/dev-i.txt
15dev -p >/tmp/kdump/dev-p.txt
16files >/tmp/kdump/files.txt
17irq >/tmp/kdump/irq.txt
18kmem -f >/tmp/kdump/pmemory.txt
19kmem -i >/tmp/kdump/memory.txt
20mach >/tmp/kdump/mach.txt
21mod >/tmp/kdump/modules.txt
22net -s >/tmp/kdump/net-s.txt
23ps -t >/tmp/kdump/ps-t.txt
24ps -c >/tmp/kdump/ps-c.txt
25sig >/tmp/kdump/sig.txt
26set >/tmp/kdump/set.txt
27task >/tmp/kdump/task.txt
28foreach task >/tmp/kdump/all-task.txt
29sym -l >/tmp/kdump/sys-l.txt
30sym -M >/tmp/kdump/sys-M.txt
31quit
32EOF
使用下面的脚本按如下方法执行:
1# getcoreinfo.sh -f vmlinux-3.0.76-0.11-default.gz vmlinux-3.0.76-0.11-default.debug vmcore
六、kdump涉及的sysctl 配置
查阅了网上很多有关kdump的资料,发现在配置kdump时,对sysctl.conf 内的一些配置也进行了调整。这里也列举下,可以根据具体的情况酌情进行修改。
1kernel.sysrq=1
2kernel.unknown_nmi_panic=1
3kernel.softlockup_panic=1
kernel.sysrq=1,如果通过/proc文件配置 ,上面的配置等价于echo 1 > /proc/sys/kernel/sysrq ,打开sysrq键的功能以后,有终端访问权限的用户将会拥有一些特别的功能。如果系统出现挂起的情况或在诊断一些和内核相关, 使用这些组合键能即时打印出内核的信息。因此,除非是要调试,解决问题,一般情况下,不要打开此功能。如果一定要打开,请确保你的终端访问的安全性。具体可以参看百度百科上给出的解释。
kernel.unknown_nmi_panic=1 ,如果系统已经是处在Hang的状态的话,那么可以使用NMI按钮来触发Kdump。开启这个选项可以:echo 1 > /proc/sys/kernel/unknown_nmi_panic 需要注意的是,启用这个特性的话,是不能够同时启用NMI_WATCHDOG的!否则系统会Panic!
kernel.softlockup_panic=1,其对应的是/proc/sys/kernel/softlockup_panic的值,值为1可以让内核在死锁或者死循环的时候可以宕机重启。如果你的机器中安装了kdump,在重启之后,你会得到一份内核的core文件,这时从core文件中查找问题就方便很多了,而且再也不用手动重启机器了。如果你的内核是标准内核的话,可以通过修改/proc/sys/kernel/softlockup_thresh来修改超时的阈值,如果是CentOS内核的话,对应的文件是/proc/sys/kernel/watchdog_thresh。
除此之外,一些站点上还会建议修改开启oops painc的功能,这个也具体根据实际需要修改吧。
PS:自动配置kdump的功能,我已经脚本化,放在了我的github上。
后记:
在后面使用中发现有出现kdump与现有模块冲突导致一直无法生成kdump的情况,这里的是VCS 的vxfs与fusion io的iomemory-vsl4模板与kdump冲突。可以通过blacklist参数将其在/etc/kdump.conf中屏蔽---suse下为/etc/sysconfig/kdump。如下:
1blacklist vxfs
2blacklist iomemory-vsl4
关于blacklist参数,redhat原厂工程师给予的解释是:blacklist参数的作用是当触发kdump时,在进入第二内核(一般称为capture kernel或kdump kernel)时不加载指定的模块。这个参数只会在发生kdump时起作用,不会影响系统正常运行。
还需要注意的是在涉及到配置文件变动时,如生成路径修改或blacklist内容增加,都需要重新生成kdump的RAM文件,不然其在发生问题时还是使用老的img RAM文件,该文件在/boot下以kdump.img结尾的文件就是:
1#ls -l /boot
2total 35024
3-rw-r--r--. 1 root root 105195 Nov 11 2013 config-2.6.32-431.el6.x86_64
4drwxr-xr-x. 3 root root 4096 Sep 15 12:12 efi
5drwxr-xr-x. 2 root root 4096 Sep 22 16:44 grub
6-rw-------. 1 root root 17135661 Sep 15 12:25 initramfs-2.6.32-431.el6.x86_64.img
7-rw------- 1 root root 11743320 Sep 22 16:35 initrd-2.6.32-431.el6.x86_64kdump.img
8drwx------. 2 root root 16384 Sep 15 12:01 lost+found
9-rw-r--r--. 1 root root 193758 Nov 11 2013 symvers-2.6.32-431.el6.x86_64.gz
10-rw-r--r--. 1 root root 2518236 Nov 11 2013 System.map-2.6.32-431.el6.x86_64
11-rwxr-xr-x. 1 root root 4128944 Nov 11 2013 vmlinuz-2.6.32-431.el6.x86_64
遇到配置变动时,可以将/boot下的initrd-uname -rkdump.img文件mv走,再通过重启kdump服务生成新的kdump.img文件。如下:

注:SUSE下重新生成使用的是/etc/init.d/boot.kdump restart 命令。
在kdump重新生成后,最好重启下主机。另一个kdump配置里需要注意的参数是:MKDUMPRD_ARGS=”–allow-missing” ,增加完该参数,会在主机每次启动时自动检查kdump配置并重新rebuild kdump.img文件。
kdump压缩
下面的命令是压缩vmcore的,请尝试操作下面的命令看是否可以压缩(可能比较耗费时间和部分系统资源),实际原理就是由原crash级别,改为级别31:
1makedumpfile -c -d 31 -x vmlinux-3.0.76-0.11-default.debug /xx/xx/vmcore /xx/shorter-vmcore
还在记得/xx/shorter-vmcore 存放目录有足够大的空间。
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/centos-kdump/3751.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.