RH442之理解CPU cache
一、CPU,内存和cache之间的关系
如今的CPU和二十几年前的相比,其精密程度和运作速度可谓天壤之别。在以前,CPU的工作频率和内存总线的频率是处于一个等级的,CPU对内存的访问速度也只是比对寄存器的访问速度要慢那么一点儿,所以CPU直接访问内存是再合理不过了。但是近十几年来,CPU发展迅猛,其工作频率大大增加,而内存的发展却无法跟上大哥的步伐。当然,并不是做不出访问频率高的内存,而是SRAM那样的高速度内存相对于作为普通内存的DRAM而言,成本过高。因此,一个折中的选择就是在CPU和内存之间引入高速缓存(cache),作为CPU和内存之间的渠道。CPU将接下来最有可能用到的数据存放在cache中,那么CPU是如何预测到接下来将要用到的数据的呢?这种预测是基于程序代码和数据在时间和空间上的局部性原理(locality)。所谓局部性原理,就是指由于循环结构的存在,在最近这段时间,同样的代码和数据很有可能再被使用。下图给出了CPU,cache和内存之间的基本关系
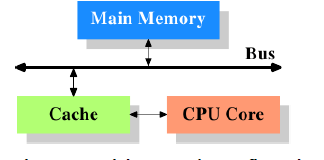
虽然计算机采用的是冯诺依曼架构,但是经验表明,将代码用的cache和数据用的cache分离开来效率更高。Intel正是从1993年开始,针对代码和数据使用相互独立的cache。随着cache的引入,cache和内存之间的工作频率差别又开始慢慢拉大,这样,又引入了下一级的cache,其容量比第一级大,速度比第一级慢。这同样是速度和经济的折中考虑,如今甚至有系统引入三级高速缓存,如下图所示
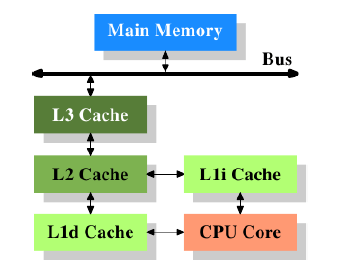
其中L1d是第一级数据缓存,L1i是第一级指令缓存,要注意的一点事该图只是一个概略的描述,实际上数据从任何一个CPU Core流向主存是不用经过高级缓存(L2,L3)的。
二、cache的操作
当CPU需要数据时,首先到cache内部去寻找,如果找到了,则称为命中了(cache hit),如果没有找到,则称为丢失(cache miss),这时CPU必须到内存去读取数据,并且将其保存在cache中以备后用。
cache中需要保存数据字在主存中的地址,cache的每个入口都被相应数据的地址所标记,当CPU要完成一次读或写操作时,会在cache中寻找匹配的标记。cache中存储的地址可以是虚拟地址,也可以是物理地址,根据cache的实现而不同。由于标记在cache中本身要占用空间,所以如果以字为粒度在cache中标记主存的地址单元那就显得有些低效。解决的办法很简单,还记得cache是基于空间的局部性原理的,由于被标记的内存字的邻近单元也有可能被使用,所以会把它们也一起加载到cache中去。因此一个cache的入口处存储的并不是单一的字,而是几个连续的字,它们被称为缓存行(cache line).
对应每个cache line,都有这样一个结构

data bolck存放的是缓存行中所保存的就是从主存取过来的数据,tag表示的是数据块在主存中的地址(并不是完整的地址),flag bits是一些在操作过程中涉及到的标志位。
而对于主存中的每个地址单元,我们都可以按下图的结构进行解析

我们已经知道,一个cache line对应的是主存中连续的几个字,那么这些字的低位对于映射一个cache line是没用的,比如说在一个32位系统中,一个cache line的大小是16个字,也就是64个字节,那么其低6位在映射一个cache时是没有用的,其作用是用来指定该内存单元在对应cache line中的偏移。Cache Set则指明了该内存单元位于哪一个cache set(一个cache set 可以包含一个或多个cache line,这与cache和内存之间的映射关系有关,在后面会进行讲解),S的长度为以2为底的log(cache sets),由于一个cache set可以包含多个cache line,所以还需要高T位的tag域来指明该内存单元是位于哪个cache line中。
下面来说说flag bits域。对于指令cache来说,flag bits位只有一位,即valid位。顾名思义,valid位指明了相应的cache line中是否装载了有效的数据。系统刚上电时,所有的cache line中的valid位都被设置为invalid.对于数据cache来说,flag bits除了有valid位外,还有一个dirty位。对于cache line来说,如果读进来的数据还未被修改,则称为clean;相反,如果数据被修改了但是还没被写回内存,这时将dirty置位表示内存和cache里的数据不同步。在SMP系统中,所有的处理器都必须协调工作保证它们所看到的内存里的内容必须是一样的,这种问题被称为缓存一致性(cache coherency).假设一个处理器的cache内对某一内存有一份clean cache copy,而这时该处理器监测到另一个处理器对相应的该内存单元发出一个写请求,那么前一个处理器将会把相应的cache line给设置为dirty,等待后者的写操作完成并进行重装载,以保证数据的同步性。显然,读操作是不会影响cache的一致性的。
三、cache和内存的关联方式(associativity)
根据cache和内存之间的映射关系的不同,cache可以分为三类:一类是全关联cache(full associative cache),一种是直接关联cache(direct mapped cache),还有一种是N路关联cache(N-ways associative cache).
1.全相联型cache
顾名思义,全相联型cache的特点就是cache内的任何一个cache line都可以映射到内存的任何一处地方,这使得全关联cache的命中率是最高的,但是CPU要想访问和内存相互映射的cache不得不把内存地址与大量的cache标志(tag)
进行比较匹配,这使得效率下降,而且对于cache,其内部电路十分复杂,因此只有容量很小的cache才会设计成全关联型的(如一些INTEL处理器中的TLB Cache).对于全关联方式,内存地址的解析方式如下图所示:

可以看到内存地址只解析成tag和offset两个域,其中tag是和cache line对应的整个物理地址,而offset即是该内存单元在cache line中的偏移。
2.直接相联型cache
设一个cache中总共存在N个cache line,那么内存被分成N等分,其中每一等分对应一个cache line,需要注意的是这里所说的1等分只是大小上的一等分,在内存上并不是完全连续的。具体的来说,假设cache的大小事4M,而一个cache line的大小是64B,那么就一共有4M/64B=65536个cache line,那么对应我们的内存,0x00000000~0x00000000+64B, 0x00000000+4M~0x00000000+4M+64B, ……,就这样被分为很多个区段,对于一个确定的cache line,如第0个,那么在这么多区段中只有一个区段能被映射进去,没有被映射进去的区段不能占用其他的cache line,这样就势必导致cache的命中率下降,所以直接关联是一种很”死”的映射方法,它的命中率是最低的,但是其实现方式最为简单,匹配速度也最快。对于直接关联方式,内存地址的解析如下图所示

该图在前篇文章中出现过,在前文中提到过cache set可以包含一个或多个cache line,那么对于直接关联cache,cache set就是一个cache line,在刚才说到的4M/64B的cache例子中,offset的长度为6位(bit 0~bit 5),cache set的长度为16位(bit 6~bit 21),用cache set域即可直接定位对应的cache line的位置。
3.N路相联型cache
N路相连cache是前两种cache的折中形式,在这种方式下,内存同样被分为很多区域,一个区域的大小为N个cache line的大小,一个区域映射到对应的N个连续的cache line,并且该区域内的单元可以映射到N个cache line中的任意一个。假设一个4-路相联cache,其大小为64M,一个cache line的大小为16K,那么总共有64M/16K=16384个cache line,但是在4-路相联的情况下,我们并不是简简单单拥有16384个cache line,而是拥有了16384/4=4096个区域(sets),每个区域有4个cache line.一个内存单元可以缓存到它所对应的set中的任意一个cache line中去。对于内存地址的解析,N路相联型和直接相联型在结构上是一样的,但是因为N路相联型的cache中的cache set有N个cache line,所以在通过内存地址单元的cache set域确定相应的set外,还要通过tag域来确定对应的cache line.
细心的朋友应该已经发现了,实际上直接相联型cache和全相联型cache只是N路相联型cache的特殊情况,当N为1时,1-路相联型cache即为直接相联型cache.而当N值和cache line的总数相等时,整个cache即为一个set,成为全相联型cache。下面再给出直接相联型cache和全相联型cache与内存的映射关系图。
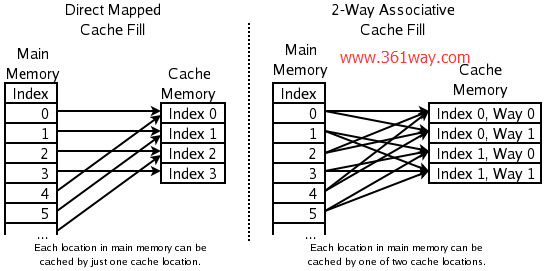
注:图中的Index即为cache set。
四、cache的写策略
内存的数据被加载到了cache后,在某个时刻其要被写回内存,对于这个时刻的选取,有如下几个不同的策略。
write-through:所谓write-through,就是指在CPU改写一个cache line后,cache line也被CPU写回内存。这种策略保证了在任何时刻,内存的数据和cache中的数据都是同步的,因此write-through最容易实现cache的一致性。显然,由于CPU要频繁地将cache里的被修改的数据写回内存,这种方法最大的缺点就是速度慢,效率低。假设一段程序在频繁地修改一个局部变量,那么尽管这个局部变量的生命周期很短,而且其他程序也用不到它,CPU依然会频繁地在cache和内存之间交换数据,这样会大大增加FSB总线(见《从硬件的体系结构开始》)上的数据流量。
write-back:write-back相对于write-through而言是一种更精炼的方法,采用write-back策略,CPU在改写了cache line后,并不是马上把其写回内存,而是将该cache line标志为dirty。只有当cache中发生一次cache miss,其他的数据要占用该cache line时,CPU才会把其写回内存。在实现write-back策略时,有一个重要的问题是需要被考虑到的,当多个处理器访问同一内存时,必须保证所有处理器所看到的内存内容是相同的,也就是一致性的问题。当一个cacacheline被一个处理器设置为dirty后,另一个处理器要访问同一内存,那么显然,该处理器真正需要的数据是前者的cache里的数据,而不是内存中还未更新的数据,后面会讲解这个问题是如何解决的。
在此之前我们再来看两种写策略,分别是write-combining和uncacheable. 这两种策略都是针对特殊的地址空间来使用的。
write-combining是针对于具体设备内存(如显卡的RAM)的一种优化处理策略。对于这些设备来说,数据从cache到内存转移的开销比直接访问相应的RAM的开销还要高得多,所以应该尽量避免过多的数据转移。试想,如果一个cache line里的字被改写了,CPU将其写回内存,紧接着又一个字被改写了,CPU又将该cache line写回内存,这样就显得低效,符合这种情况的一个例子就是显示屏上水平相连的像素点数据。write-combining策略的引入就是为了解决这种问题,顾名思义,这种策略就是当一个cache line里的数据一个字一个字地都被改写完了之后,才将该cache line写回到内存中。
uncacheable内存是一部分特殊的内存,该内存里的数据时硬编码的,可以不需要CPU的控制就能实现一些功能,比如用来访问一些链接在外部总线(如PCIe,etc)的设备而被映射的地址空间。PCI card中的内存可以不依赖CPU的控制就能发生改变,所以它是不需要被缓存的。
五、多处理器支持
在一个典型的系统中,几个cache通过共享总线来连接到内存,而这些cache又分别附属给几个不同的CPU。这些cache的共同目标就是尽可能减少对主存的使用。为了解决cache的一致性问题,cache的设计者们引入了很多不同的协议,其中MESI协议被广泛用于支持write-back cache. 还记得在前面说过,数据cache中用两位来表示一个cache line的状态,MESI协议中利用这两位组成4种状态,分别是Modified,Exclusive,Shared和Invalid,下面说明这四种状态的含义.
Modified:本地处理器修改了cache line中的数据,并且数据只存在于这一个cache中,在其他cache中没有备份。
Exclusive:cache line中的数据没有被修改,并且数据只存在于这一个cache中,在其他cache中没有备份。
Shared:cache line中的数据没有本修改,该数据有可能在其他cache中有备份。
Invalid:cache line中的数据是无效的。
下面给出各个状态之间的转换图:
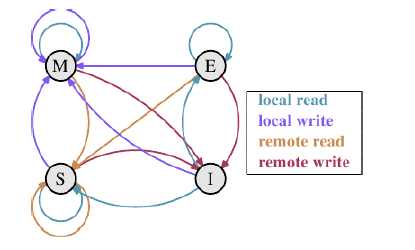
每两个状态之间的转换说明,网上有一位朋友描述得很详细,我将他总结的贴在下面
| 当前状态 | 事件 | 行为 | 下一个状态 |
|---|---|---|---|
| I(Invalid) | Local Read | 如果其它Cache没有这份数据,本Cache从内存中取数据,Cache line状态变成E; 如果其它Cache有这份数据,且状态为M,则将数据更新到内存,本Cache再从内存中取数据,2个Cache 的Cache line状态都变成S; 如果其它Cache有这份数据,且状态为S或者E,本Cache从内存中取数据,这些Cache 的Cache line状态都变成S | E/S |
| Local Write | 从内存中取数据,在Cache中修改,状态变成M; 如果其它Cache有这份数据,且状态为M,则要先将数据更新到内存; 如果其它Cache有这份数据,则其它Cache的Cache line状态变成I | M | |
| Remote Read | 既然是Invalid,别的核的操作与它无关 | I | |
| Remote Write | 既然是Invalid,别的核的操作与它无关 | I | |
| E(Exclusive) | Local Read | 从Cache中取数据,状态不变 | E |
| Local Write | 修改Cache中的数据,状态变成M | M | |
| Remote Read | 数据和其它核共用,状态变成了S | S | |
| Remote Write | 数据被修改,本Cache line不能再使用,状态变成I | I | |
| S(Shared) | Local Read | 从Cache中取数据,状态不变 | S |
| Local Write | 修改Cache中的数据,状态变成M, 其它核共享的Cache line状态变成I | M | |
| Remote Read | 状态不变 | S | |
| Remote Write | 数据被修改,本Cache line不能再使用,状态变成I | I | |
| M(Modified) | Local Read | 从Cache中取数据,状态不变 | M |
| Local Write | 修改Cache中的数据,状态不变 | M | |
| Remote Read | 这行数据被写到内存中,使其它核能使用到最新的数据,状态变成S | S | |
| Remote Write | 这行数据被写到内存中,使其它核能使用到最新的数据,由于其它核会修改这行数据,状态变成I | I |
MESI状态迁移
原文出处:http://blog.csdn.net/vanbreaker/article/details/7477853
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/cpu-cache/5447.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.