回归ping的问题—如何批量拨测
一、有关ping
ping命令是在学习计算机不久后就会接触的一个基础命令,关于ping的衍生类命令更是不胜枚举,像:hrping、tping、fping、nmap、echoping、hping(目前是hping3)等等。当把一个简单的问题提升到一个量级的时候就不再是一个简单的问题。10台、100台主机,通过简单的for循环配合ping命令就可以搞定所有主机的存活性检测,但如果有5000台机器,想让你在每1-2分钟内获取所有主机是否都是网络正常的,你该去怎么操作?
二、拨测问题
回到上面提到的,现网主机有几千台甚至上万台的时候,单一的基础功能需求可能也是一个难题。在很多公司里,可能部署的有zabbix、nagios、Open-Falcon之类的监控系统,而且也集成的有关于ping网络质量的绘图。有主机宕机也可以通过配置策略进行告警。但对于设备量比较多的公司,单一监控往往也是致命的,人为原因、触发器策略、监控系统网络问题等等都可能会导致错过某一条严重的告警。
目前公司大约设备4000台左右,以linux为主,之前找的某厂家来做的策略是除了原有的zabbix平台外,再加一个ssh拨测系统,不过ssh这个拨测相当慢,一般来说一台主机要5分钟左右才能再进行下一次拨测。而对于虚拟机而言,2-3分钟之内完成重启很正常(所以ssh的拨测方式对于检测主机存活来的及时性来说只能是聊胜于无)。后来在zabbix上通过增加uptime时间类的监测可以发现重启的主机,并进行上告。而一个合格的检测系统,系统能花较少的资源能在1-2分钟内完成一轮几千台设备的网络可用性检查。
三、设计拨测系统
1、ping工具选型
常用的比较高效的网络可用性检查工具有两个:ping、nmap。对于标准段主机(如192.168.1.0/24), 网络检测时使用nmap -sn处理和返回速度还是非常快的,但对一个机房来说,总有设备的上下线,不可能会有的网段都刚好占用完,或连续的空缺。在处理各段有欠缺的或存在不确定性的主机列表表的网络可用性检测(实际就是读文件列表文件),使用nmap就效率大打折扣。而fping在此方面就显的比较吊了,见下图:
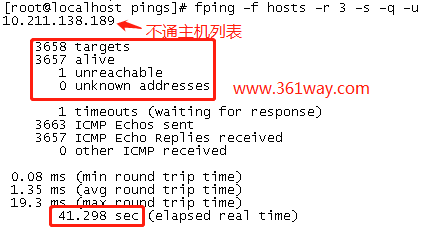
3658台设备,ping一次的耗时是41.3秒左右,1分钟不到,搞定了一轮主机的网络检测。并且找出了不通的主机是哪一台。并且对不通的主机,进行了三次重试检测。OK,基础工具定了,我们再来看数据源的问题。
2、数据源
这里的数据源要用的到就是目前在网的所有主机IP地址列表,这个可以从两个地方来CMDB 或监控系统,就看哪个及时性更好了。一般来说很多大公司的CMDB会以自动采集配合手工录入进行(牛B的互联网公司也许不该列,国企大厂基本都在此列),所以一般并不一定时时性很强(下线可能会有很多内部流程,到真正在CMDB标记为下线状态的时候,可能是在工单流转完成后)。但监控系统采用的数据肯定是最准的,下线设备肯定会从监控平台去掉了,不然一直告警也不对啊,维护设备一般会在监控平台标记为不可用或维护。这里以zabbix 监控为例吧,可以通过如下命令查到所有在用的设备列表:
1select ip from interface where hostid not in (select hostid from hosts where status=1);
状态为1的主机是什么设备呢?
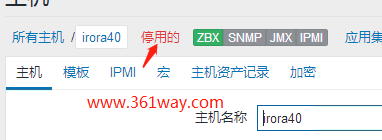
上面箭头指的应该都认识吧。
3、黑名单
在进行设备检测过程中,我们肯定会遇到一些设备让其在一段时期内不再进行检测的。比如某台设备总是有网络抖动,原因可能暂时不明,但拨测系统总是报该主机异常,问题已知,需进一步分析的,想暂时进行屏蔽。怎么搞?
简单的shell就能搞定,更不用说其他更高级的语言了。先mysql -e从数据库里执行上面的SQL ,将主机导到export文件中,黑名单主机存到blacklist文件中,两个文件排序后,执行diff 处理,再进行grep处理和awk处理,就获取了我们想要检查的所有主机列表了吧。
4、告警压制
这是一个成熟的监控系统一定要考虑的问题,我们不能简单粗暴一个死循环搞定,一旦某机器出问题,就要狂刷告警了。比如,一台有问题的主机,在该台主机告警未恢复之前,最多告警告警三次(可以理解为同一事件id)。当天中间有恢复的,又会变一个新的事件ID。这个处理方法也有常用的两种:
1、可以通过定一个文本文件,每次检测到该IP异常了,加入该文件,下次有异常主机时,和该文件进行匹配,发现该IP了,后面的告警次数统计加1 ,当检测到次数为3时,忽略跳过。 后面检测到异常的主机里没有这个IP时,将该IP从该文件中移除。
2、可以通过数据库,如此简单的系统,如果考虑数据库的话,按我的思数优先选择SQLite,其实mysql ,oracle就算了,太重量级。上面提到的一些相关文件,可以都存到数据库里,当然更复杂点,可以加上事件ID的概念。
四、上线或商用的细节
上面啰嗦的一堆,流程图这里懒得画了,上个手绘版的吧。当然这里有一些细节没画上,这里再补充下。
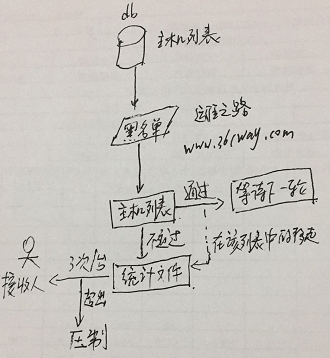
1、因为一个公司的设备一般变动都是以天为单位的,为减少去数据库查询的次数,需要设置一个大轮询。比如在一天之内,只从zabbix数据库里拉取一次,后面存在本地库或文件,再和blacklist比对。大轮询里面会有N次每隔1-2分钟检测一次的小轮询;
2、大公司或商用,还要考虑web封装界面化,比如,告警接收人、黑名单、每次检测间隔、通知方式(短信、邮件、钉钉、微信)、压制次数等都可以在web界面上配置;
3、异常主机是否还需要日志化,便于回溯统计。
五、fping原理及代码
在能检索到的相关文档里,目前我能找到的关于fping的原理只有这么一句话:与标准ping工具不同,fping会在收到单个应答后停止发送 ICMP 回显请求。 在接收到回复时,它将显示对应该地址的主机是活动的。 或者,如果未从地址接收到响应,则在确定主机不可达之前,fping通常尝试联系系统四次(这里应该有误,按我从参数里的理解是三次)。无奈去读原码,其目前代码也是放在github上的(神奇的是fping是2002年就已经面世的神器),核以文件代码地址: 。
搬着脚指头基本也能想得到,这又是一个C语言搞出来的工具,在没看代码之前,按我的理解,一次性解决多台主机的ping,可能会用到多线程、多进程或多协程。结果在代码里跟本找不到有关thread或者routine这样的关键字,看到最多的就是结构体成员运算与指针—-好神奇的语言,如神奇的思维。另外还用到一个seqmap的东西,还没深研究。先看fping.c主文件吧,这里只列几处吧:
1代码900-924行,一次性读取所有IP行
2else if (filename) {
3 FILE* ping_file;
4 char line[132];
5 char host[132];
6 if (strcmp(filename, "-") == 0)
7 ping_file = fdopen(0, "r");
8 else
9 ping_file = fopen(filename, "r");
10 if (!ping_file)
11 errno_crash_and_burn("fopen");
12 while (fgets(line, sizeof(line), ping_file)) {
13 if (sscanf(line, "%s", host) != 1)
14 continue;
15 if ((!*host) || (host[0] == '#')) /* magic to avoid comments */
16 continue;
17 add_name(host);
18 }
19 fclose(ping_file);
954-981行,分配内存
1table = (HOST_ENTRY**)malloc(sizeof(HOST_ENTRY*) * num_hosts);
2 if (!table)
3 crash_and_burn("Can't malloc array of hosts");
4 cursor = ev_first;
5 for (num_jobs = 0; num_jobs i = num_jobs;
6 /* as long as we're here, put this in so names print out nicely */
7 if (count_flag || loop_flag) {
8 n = max_hostname_len - strlen(cursor->host);
9 buf = (char*)malloc(n + 1);
10 if (!buf)
11 crash_and_burn("can't malloc host pad");
12 for (i = 0; i pad = buf;
13 }
14 cursor = cursor->ev_next;
15 }
16 init_ping_buffer_ipv4(ping_data_size);
17#ifdef IPV6
18 init_ping_buffer_ipv6(ping_data_size);
19#endif
send_ping函数字面意思也能理解吧,发送ping请求。ev_enqueue函数,根据事件时间进行排队ping队列,时间长的排在后面。IPv4下的ping检测方法在socket4.c文件内,同理,ipv6的为ipv6.c。而且作者代码上的注释还是比较清晰的,基本看注释也能知道干嘛的。已经半夜2点,再者本人也确实比较菜,也挖不出什么东东了。本篇就到这里吧。
最后加个链接,关于多主机ping网络检测,实际上2016年的时候这些工具和检测方法当时都考量过,当时只是使用了somkeping进行测试—-《nginx+smokeping安装配置》,并未有单独搞一个系统的迫切压力。而fping上面也提到的2002年就已经面世的工具,也并不是什么新鲜玩意,除了somkeping依赖此外,像zabbix、netdata等很多监控平台也都有在ping检测方面使用的该工具。
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/fping-check-system/5847.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.