SRE运维(六)如何正确制定SLO
设计SLO的目的是什么?设定SLO目标是面向客户感知的,当系统的表现高于SLO阀值时,用户感知是满意的,在低于这个值时,用户可能就会要抱怨了。不过客户满意度这是个模糊的概念,而且在不同情况下,即像你的系统的SLO达到了100%,客户可能也是不满意的。为什么会这样?先从SLO的平衡开始。
一、SLO目标的平衡
老马老师(马克思)提出了辩证唯物主义的观点,美帝下的Google里估计有不少社会主义学者,Google提出了100%的可靠性并不属于SLO工程文化(很客观很辩证啊!)。为什么会这样说,我们先来分析下为什么100%的可靠性面对的对外部问题,分析完我们再做一个总结。

这里列了一个十字分析图,可以从系统内部和外部、应用和交付四个维度来说明。首先从外部来讲,比如之前提到过的例子,光缆被挖断了。像BAT这种级别的容灾做的好吧,不过他们在遇到这种情况下,切换容灾不也是一样算时间吗?这里也会计到用户感知里的。所以及外部上你不能避免各种黑天鹅出现。内部呢,想想你对外提供的应用涉及到多少东西,硬件、OS、数据库、中间件、应用本身,保不起哪一个就出了bug抽风了。你高可用做的再好,总有那0.001%的用户会受到影响吧?接下来再看应用本身和交付的一个矛盾,回到开头讲到的话,为什么有时候100%的SLO在不同情况下也会降低满意度呢?比如,你有一个网站对外提供服务—-我们称之为完美服务吧,老牛B了,10年没坏过,内部外部应用系统各种异常都没出现过,之前客户的满意意也很高,不过放在现在就行不通了。为什么?现在是移动互联网时代,你得有APP或者小程序啊,对吧。为什么你没有?因为你的维护和交付团队365*7*24都在忙网站的100%可靠性。所以这里还存在一个可靠性和新功能之间的悖论。车票还都去车站,转帐必须去银行,这在不同时代客户的满意度肯定是不同的,需要讲究SLO选取也在与时俱进,产功功能性交付与SLO可靠性的平衡。

二、可度量的SLI与SLO
SLO实际上就是对SLI的量化,上面提到了SLO是面向于用户满意度的,用户满意度又是一个很模糊的概念。那SLI怎么选取呢?因为本身我自己的个人博客维护了10多年了,这里就还以web为例,人在浏览网页或者微博贴子时什么能衡量用户满意指标呢?(抛却内容本 身,因为那不是SRE块负责的内容。)我这里想到两个:
- 页面是否可以正常打开
- 页面打开的时间长短
那接下来我们参照百分比率的计算方式,可以做一个设计,我们可以通过监控的方式获取所需的数据,这种实现方式,可以由日志(根据返回码,比如http code是5xx这种肯定是内部有问题啊),还可以由外部监控系统进行用户访问请求(站点可用性 检测 监控宝),还有APM在页面上加上JS探测脚本(百度统计、听云),甚至我们还可以基于这三种方式做一个权重的计算得出正常打开的百分比。同样,除了网站通断,这三种方式还会附带有页面请求所耗费的时长,我们同样可以计算出一段时间内的平均打开时长。对应的API的计算也会变的比较容易,这里也根据google的做法,使用prometheus表示法。比如站点可用性指标:
sum(rate(http_requests_total{host=”api”,status!~”5..”}[7d]))
/
sum(rate(http_requests_total{host=”api”}[7d]))
这个是计算一周的正常请求和总请求的比率,同样我们可以修改条件,看1天、1月、1年的,还可以和granfana结合后在一屏上进行展示,同样也可以根据历史数据进行SLO目标的设置,比如可用性要高于98%。时延这个我们可以做一些条件,比如请求大于500ms的我们认为是慢请求,可以使用如下表达式得出慢速请求:
http_request_duration_seconds {host=”api”,le=”0.5″}
同样套用上面可用性的做法,我们可以得出请求大于500ms的百分比,基于这个也可以设定个SLO目录,90%的请求时延小于500ms。
这里也可以使用累积直方图的统计方式,用histogram_quantile实现,histogram_quantile(φ float, b instant-vector) 从 bucket 类型的向量 b 中计算 φ (0 ≤ φ ≤ 1) 分位数(百分位数的一般形式)的样本的最大值。(有关 φ 分位数的详细说明以及直方图指标类型的使用,请参阅直方图和摘要)。向量 b 中的样本是每个 bucket 的采样点数量。每个样本的 labels 中必须要有 le 这个 label 来表示每个 bucket 的上边界,没有 le 标签的样本会被忽略。直方图指标类型自动提供带有 _bucket 后缀和相应标签的时间序列。
histogram_quantile(0.9, rate(http_request_duration_seconds_bucket[7d]))
histogram_quantile(0.99, rate(http_request_duration_seconds_bucket[7d]))
上面第一个是取最近1周http_request_duration_seconds_bucket的90% 的样本的最大值,rate是取平均量。不过在使用histogram_quantile计算时需要注意,其对应的参数b不能过大,也不能过小。过大过小会存在以下问题:
因为 histogram 并不记录所有数据,只记录每个 bucket 下的 count 和 sum。如果 bucket 设置的不合理,会产生不符合预期的 quantile 结果。比如最大 bucket 设置的过小,实际上有大量的数据超出最大 bucket 的范围,最后统计 quantile 也只会得到最大 bucket 的值。因此如果观察到 histogram_quantile 曲线是笔直的水平线,很可能就是 bucket 设置不合理了。
另一种情况是 bucket 范围过大,绝大多数记录都落在同一个 bucket 里的一段小区间,也会导致较大的偏差。例如 bucket 是 100ms ~ 1000ms,而大部分记录都在 100ms ~ 200ms 之间,计算 P99 会得到接近于 1000ms 的值,这是因为 Prometheus 没记录具体数值,便假定数据在整个 bucket 内均匀分布进行计算。Prometheus 的官方文档里也描述了这个问题。
所以为了避免这种参数设置的不合理,在前期设置调研的时候我们会利用直方图和多区间的http_request_duration_seconds {host=”api”,le=”0.5″}统计结合来确认这个SLO的目标。通过一段时间的分析可能你就可以设定SLO的时延目标是90%小于500ms,99%小于900ms。
三、SLI指标的分类
上面只是以简单的web应用为例,现实中我们不可能只是web,所以可以把组件类型抽象化,google抽象化了三种:
请求驱动(request-driven):
流水线(pipeline):
存储(storage):
根据以上类型我们就可以细化为抽象的SLI类型,见下表:

上面的分类并不是孤立使用的,有时候要结合使用,比如网盘服务,除了持久性要求,还有可用性和低延时要求。除此之外,还有RED和USE的黄金指标分类方式:
USE 方法(来自 Brendan Gregg):利用率,饱和度,错误
RED 方法(来自 Tom Wilkie):速率,错误和持续时间
可以看到这和上面的分类有些是重叠的,其实这本质上没有区别。这类分类我们可以做下解释:
请求率 – 请求率,请求 / 秒。
错误率 – 错误率,误差 / 秒。
延迟 – 响应时间,包括队列 / 等待时间,以毫秒为单位。
饱和度 – 某些东西的超负荷程度如何,直接通过诸如队列深度(或有时并发)之类的东西来衡量。当系统饱和时变为非零。
利用率 – 资源或系统的繁忙程度。通常表示 0-100%,对预测最有用(饱和度通常对警报更有用)。
以便于理解的角度我们可以简单的分类如下:
性能
- 响应时间(latency)
- 吞吐量(throughput)
- 请求量(qps)
- 实效性(freshness)
可用性
- 运行时间(uptime)
- 故障时间/频率
- 可靠性
质量
- 准确性(accuracy)
- 正确性(correctness)
- 完整性(completeness)
- 覆盖率(coverage)
- 相关性(relevance)
内部指标
- 队列长度(queue length)
- 内存占用(RAM usage)
因素人
- 响应时间(time to response)
- 修复时间(time to fix)
- 修复率(fraction fixed)
如果Service是第一次设置SLO,可以遵循以下原则
- 测量系统当前状态
- 设置预期(expectations),而不是保证(guarantees)
- 初期的SLO不适合作为服务质量的强化工具
- 改进SLO
- 设置更低的响应时间、更改的吞吐量等
- 保持一定的安全缓冲
- 内部用的SLO要高于对外宣称的SLO
- 不要超额完成
- 定期的downtime来使SLO不超额完成
四、国内大厂的做法
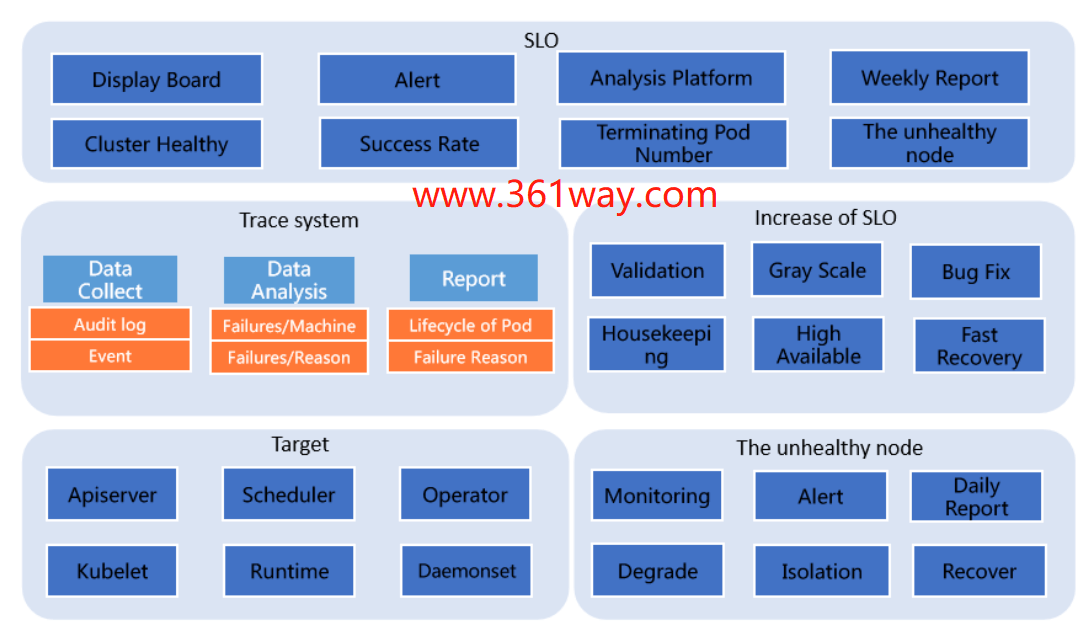
可以看出蚂蚁集团在 SLO 体系架构时,分成了五块:SLO、Trace system、Increase of SLO、Target 和 The unhealthy node 。其实这五个方面,可以归纳为两点,一个方面用于向终端用户 / 运维人员展示当前集群各项指标状,另一方面是各个组件相互协作,分析当前集群状态,获取影响 SLO 的各项因素,为提升集群 pod 交付成功率提供数据支持。前面一部分是面向用户体验的,后面一部分是面向问题的快速定位和恢复的。该部分可以参看:蚂蚁集团如何在大规模 Kubernetes 集群上实现高 SLO
参考页面:
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/how-to-set-slo/6478.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.