python中的map/reduce/filter函数
近期公司有项目上使用的代码涉及调用外部API接口进行多页请求,并需要把对应的数据返回后进行处理。开发人员使用了多层for嵌套循环处理,从逻辑上看,确实for循环比较简单也比较容易理解,不过性能上会略差一些。在进行响应时延过高的问题分析时,通过换用map函数代替for可以进行效率的提升。本篇就总结下python下的map、reduce方法。
一、map方法
map()方法会将 一个函数 映射到序列的每一个元素上,生成新序列,包含所有函数返回值。他传入的参数是一个函数和一个list序列。在python2.X中 map函数返回的是list列表,在python3新版本里返回的是迭代器,需要通过list(map(fun1,list1))才可以返回结果。
map(function_to_apply, list_of_inputs)
function_to_apply代表函数、list_of_inputs代表输入序列。比如,实现一个求平方的操作:
1items = [1, 2, 3, 4, 5]
2squared = list(map(lambda x: x**2, items))
3# 等价于下面的写法
4items = [1, 2, 3, 4, 5]
5def f(x):
6 return x**2
7squared = list(map(f, items))
8# 等价于以下for循环的写法
9items = [1, 2, 3, 4, 5] # 列表
10squared = []
11for i in items:
12 squared.append(i**2)
上面的函数,使用map内部实现的原理如下:

map()方法会将 一个函数 映射到序列的每一个元素上,生成新序列,包含所有函数返回值。也就是说序列里每一个元素都被当做x变量,放到一个函数f(x)里,其结果是f(x1)、f(x2)、f(x3)……组成的新序列。
二、reduce函数
相比于map,reduce的操作稍稍难理解一点点。它也是规定一个映射,不过不是将一个元素映射成一个结果。而是将两个元素归并成一个结果。并且它并不是调用一次,而是依次调用,直到最后只剩下一个结果为止。其语法如下:
1reduce(function, iterable[, initializer])
2function:代表函数
3iterable:序列
4initializer:初始值(可选)
以下列出个实现阶乘的示例如下:
1# 导入reduce
2from functools import reduce
3# 定义函数
4def f(x,y):
5 return x*y
6# 定义序列,含1~10的元素
7items = range(1,11)
8# 使用reduce方法
9result = reduce(f,items)
10print(result)
依次求和的示例如下:
1from functools import reduce
2def f(a, b):
3 return a + b
4print(reduce(f, [1, 2, 3, 4]))
5# 其等价于以下实现
6print(reduce(lambda x, y: x + y, [1, 2, 3, 4]))
其内部执行原理如下:
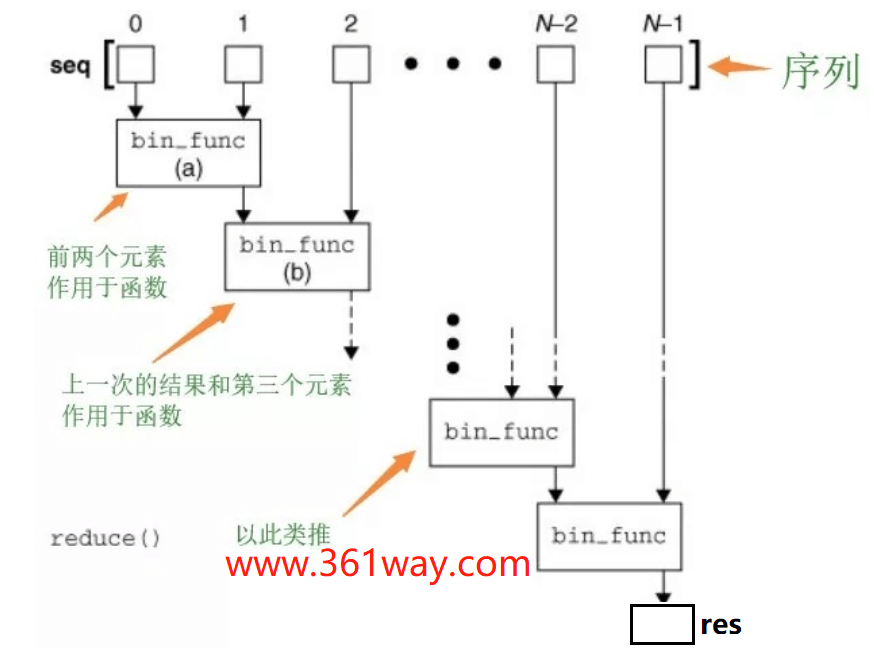
map和reduce相同的是接受传入的参数都是函数和list参数,不过reduce可以接受第三个参。
三、map与reduce结合
在大数据里会有一个mapreduce概念,其实在python里两个函数结合起来,确实可以达到mapreduce的效果,这里给出一个代词数量统计的示例,代码如下:
1from collections import Counter
2texts = ['apple bear peach grape', 'grape orange pear']
3def mp(text):
4 words = text.split(' ')
5 return Counter(words)
6print(reduce(lambda x, y: x + y, map(mp, texts)))
执行结果如下:
1>>> print(reduce(lambda x, y: x + y, map(mp, texts)))
2Counter({'grape': 2, 'apple': 1, 'bear': 1, 'peach': 1, 'orange': 1, 'pear': 1})
四、filter函数与compress函数
filter的英文是过滤,所以它的使用就很明显了。它的用法和map有些类似,我们编写一个函数来判断元素是否合法。通过调用filter,会自动将这个函数应用到容器当中所有的元素上,最后只会保留运行结果是True的元素,而过滤掉那些是False的元素。例如,以下通过推导式进行奇数提取的,就可以通过filter函数实现提取:
1arr = [1, 3, 2, 4, 5, 8]
2[i for i in arr if i % 2 > 0 ]
3#使用filter实现如下:
4list(filter(lambda x: x % 2 > 0, arr))
和filter函数类似的,还有一个compress函数,其是在itertools包里的一个函数。可以通过传给的布尔值列表,找到值为真的结果:
1from itertools import compress
2student = ['xiaoming', 'xiaohong', 'xiaoli', 'emily']
3scores = [60, 70, 80, 40]
4>>> pass = [i > 60 for i in scores]
5>>> print(pass)
6[False, True, True, False]
7>>> list(compress(student, pass))
8['xiaohong', 'xiaoli']
五、写在最后
python已经帮我们造好了很多比较容易实现的方法,可以通过引用这些方法,快速的达到我们想法实现的目标,在实际操作过程中,要尽可能的避免使用大的for循环嵌套。最后再列一个示例,可以替代for循环的总结:
1numbers = [1,2,3,4,5,6]
2odd_numbers = []
3squared_odd_numbers = []
4total = 0
5# filter for odd numbers
6for number in numbers:
7 if number % 2 == 1:
8 odd_numbers.append(number)
9# square all odd numbers
10for number in odd_numbers:
11 squared_odd_numbers.append(number * number)
12# calculate total
13for number in squared_odd_numbers:
14 total += number
15# calculate average
16#上面的内容,可以通过如下函数简单实现:
17from functools import reduce
18numbers = [1,2,3,4,5,6]
19odd_numbers = filter(lambda n: n % 2 == 1, numbers)
20squared_odd_numbers = map(lambda n: n * n, odd_numbers)
21total = reduce(lambda acc, n: acc + n, squared_odd_numbers)
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/map-reduce-filter/6599.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.