Python读取/导出(写入)CSV文件
想要用python处理csv文件。去查了下,python中本身就自带csv模块。然后参考在线手册:http://docs.python.org/2/library/csv.html
一、用python生成csv
按照手册的例子,试了试:
1import csv
2with open('eggs.csv', 'wb') as csvfile:
3 spamwriter = csv.writer(csvfile, delimiter=' ',quotechar='|', quoting=csv.QUOTE_MINIMAL)
4 spamwriter.writerow(['Spam'] * 5 + ['Baked Beans'])
5 spamwriter.writerow(['Spam', 'Lovely Spam', 'Wonderful Spam'])
然后生成的文件,原始数据为:
1# cat eggs.csv
2Spam Spam Spam Spam Spam |Baked Beans|
3Spam |Lovely Spam| |Wonderful Spam|
excel打开结果为:

很明显,不是想要的结果,因为只是一列,实际应该是6列才对。看了下参考手册,发现如下信息:
csv.writer(csvfile[, dialect=’excel’][, fmtparam])
csv.writer(csvfile[, dialect=’excel’][, fmtparam])
Return a writer object responsible for converting the user’s data into delimited strings on the given file-like object. csvfile can be any object with a write() method. If csvfile is a file object, it must be opened with the ‘b’ flag on platforms where that makes a difference. An optional dialect parameter can be given which is used to define a set of parameters specific to a particular CSV dialect. It may be an instance of a subclass of the Dialect class or one of the strings returned by the list_dialects() function. The other optional fmtparam keyword arguments can be given to override individual formatting parameters in the current dialect. For full details about the dialect and formatting parameters, see section Dialects and Formatting Parameters. To make it as easy as possible to interface with modules which implement the DB API, the value None is written as the empty string. While this isn’t a reversible transformation, it makes it easier to dump SQL NULL data values to CSV files without preprocessing the data returned from a cursor.fetch* call. All other non-string data are stringified with str() before being written.Return a writer object responsible for converting the user’s data into delimited strings on the given file-like object. csvfile can be any object with a write() method. If csvfile is a file object, it must be opened with the ‘b’ flag on platforms where that makes a difference. An optional dialect parameter can be given which is used to define a set of parameters specific to a particular CSV dialect. It may be an instance of a subclass of the Dialect class or one of the strings returned by the list_dialects() function. The other optional fmtparam keyword arguments can be given to override individual formatting parameters in the current dialect. For full details about the dialect and formatting parameters, see section Dialects and Formatting Parameters. To make it as easy as possible to interface with modules which implement the DB API, the value None is written as the empty string. While this isn’t a reversible transformation, it makes it easier to dump SQL NULL data values to CSV files without preprocessing the data returned from a cursor.fetch* call. All other non-string data are stringified with str() before being written.
将上面的代码更改为:
1import csv
2with open('eggs.csv', 'wb') as csvfile:
3 #spamwriter = csv.writer(csvfile, delimiter=' ',quotechar='|', quoting=csv.QUOTE_MINIMAL)
4 spamwriter = csv.writer(csvfile, dialect='excel')
5 spamwriter.writerow(['Spam'] * 5 + ['Baked Beans'])
6 spamwriter.writerow(['Spam', 'Lovely Spam', 'Wonderful Spam'])
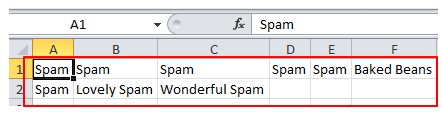
1# cat eggs.csv
2Spam,Spam,Spam,Spam,Spam,Baked Beans
3Spam,Lovely Spam,Wonderful Spam
使用python的csv生成excel所兼容的csv文件的话,主要就是创建writer时的参数时要有dialect=’excel’,就可以了。
二、用Python读取从excel导出的csv文件
再去尝试用python处理,从excel 2010导出的一个csv文件:

使用如下代码:
1import csv
2with open('excel_2010_ms-dos.csv', 'rb') as csvfile:
3 #spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|')
4 spamreader = csv.reader(csvfile, dialect='excel')
5 for row in spamreader:
6 print ', '.join(row)
运行结果如下:
1# python test_csv.py
2a1, b1, c1, d1
3a2, , c2,
4, b3, ,
只要指定了对应的dialect=’excel’,也是可以很方便的使用python的csv处理excel所导出的ms-dos的csv文件的。
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/python-csv-rw/4380.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.