python异步 I/O模块gevent
一、gevent与monkey patch
在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。在任何时刻,只有一个协程在运行。这与multiprocessing或threading等提供真正并行构造的库是不同的。 这些库轮转使用操作系统调度的进程和线程,是真正的并行。
提到gevent就要提下猴子补丁(monkey patch),monkey patch指的是在运行时动态替换,一般是在startup的时候。一般在使用gevent程序的最开头的地方会加入gevent.monkey.patch_all() ,其作用是把标准库中的thread/socket等给替换掉。这样我们在后面使用socket的时候可以跟平常一样使用,无需修改任何代码,但是它变成非阻塞的了。
先来个简单的批量抓取页面的示例:
1#!/usr/bin/env python
2# coding=utf-8
3# code from www.361way.com
4from gevent import monkey
5monkey.patch_all()
6import urllib2
7from gevent.pool import Pool
8def geturls():
9 urls = []
10 for v in range(0,1000,10):
11 url = 'http://www.baidu.com/s?wd=site%3A361way.com&pn=' + str(v)
12 urls.append(url)
13 return urls
14def download(url):
15 return urllib2.urlopen(url).read()
16if __name__ == '__main__':
17 urls = geturls()
18 pool = Pool(20)
19 print pool.map(download, urls)
上面的示例中,在运行前就先打上了猴子补丁。后面又用到了Pool的概念,是不是感觉有似曾相似的感觉,这个在multiprocessing模块中也有相应的pool.map的用法。
gevent也经常会和flask、tornado等web框架结合起来来用。这里再来个基于gevent实现的echo回显服务器:
1#!/usr/bin/env python
2# coding=utf-8
3# code from www.361way.com
4from gevent.server import StreamServer
5def connection_handler(socket, address):
6 for l in socket.makefile('r'):
7 socket.sendall(l)
8if __name__ == '__main__':
9 server = StreamServer(('0.0.0.0', 8000), connection_handler)
10 server.serve_forever()
这里通过telnet 主机IP 8000后,无论你输入什么,主机就会回什么给你 。在回显服务器的基础上再做个增强功能,可以做一个在线聊天服务:
1#!/usr/bin/env python
2# coding=utf-8
3# code from www.361way.com
4import gevent
5from gevent.queue import Queue
6from gevent.server import StreamServer
7users = {} # mapping of username -> Queue
8def broadcast(msg):
9 msg += '\n'
10 for v in users.values():
11 v.put(msg)
12def reader(username, f):
13 for l in f:
14 msg = '%s> %s' % (username, l.strip())
15 broadcast(msg)
16def writer(q, sock):
17 while True:
18 msg = q.get()
19 sock.sendall(msg)
20def read_name(f, sock):
21 while True:
22 sock.sendall('Please enter your name: ')
23 name = f.readline().strip()
24 if name:
25 if name in users:
26 sock.sendall('That username is already taken.\n')
27 else:
28 return name
29def handle(sock, client_addr):
30 f = sock.makefile()
31 name = read_name(f, sock)
32 broadcast('## %s joined from %s.' % (name, client_addr[0]))
33 q = Queue()
34 users[name] = q
35 try:
36 r = gevent.spawn(reader, name, f)
37 w = gevent.spawn(writer, q, sock)
38 gevent.joinall([r, w])
39 finally:
40 del(users[name])
41 broadcast('## %s left the chat.' % name)
42if __name__ == '__main__':
43 import sys
44 try:
45 myip = sys.argv[1]
46 except IndexError:
47 myip = '0.0.0.0'
48 print 'To join, telnet %s 8001' % myip
49 s = StreamServer((myip, 8001), handle)
50 s.serve_forever()
可以好几个窗口telnet IP 8001,登录上以后 ,回首先让输入用户名,接下来任何人输入的内容都会在各个用户的窗口显示 。接下来我们分析原理。
二、同步 I/O
同步I/O是指每个I/O操作被允许阻塞,直到它完成。为了在同一时间扩展用户规模,我们需要的线程和进程。每个线程或进程被允许单独阻塞等待I/O操作。因为我们有完整的并发性,这阻塞不影响其他操作;从每个线程/进程的角度看,世界将停止直到操作完成。当结果准备就绪时,操作系统会恢复线程/进程。

线程的缺点:糟糕的性能。请参阅 Dave Beazley 的 GIL 笔记。还有高内存使用。线程在Linux中分配堆栈内存(请参阅ulimit -s)。这是对 Python 是没有用的 —— 相对较少线程就会让你耗尽内存。
进程的缺点:没有共享的内存空间。还有高内存使用,因为堆栈分配和写入时复制(译注:copy-on-write)。线程在Linux中就像一种特殊的进程;内核结构都或多或少是相同的。
三、异步I/O
所有的异步I/O都依赖于同一种模式.它不在于代码如何运行,而在于在何处完成等待.多路I/O操作需要统一做等待处理,于是,等待只在代码中的一个地方出现.当事件触发的时候,异步系统需要恢复等待这个事件的代码块.
接下来的问题不在于在一个地方做等待,而在于如何恢复等待接收事件的代码块.
这里有一些方法,关于如何组织一个单线程程序,所有的等待只在代码中的一个地方完成.在下面的事件循环代码中,关于resume()和waiter有一些不同的实现方法:
1read_waiters = {}
2write_waiters = {}
3timeout_waiters = []
4def wait_for_read(fd, waiter):
5 read_waiters[fd] = waiter
6wait_for_write = write_waiters.___setitem__
7def event_loop():
8 while True:
9 readfds = read_waiters.keys()
10 writefds = write_waiters.keys()
11 read, write, error = select.select(
12 readfds, # waiting for read
13 writefds, # waiting for write
14 readfds + writefds, # waiting for errors
15 )
16 for fd in read:
17 resume(read_waiters.pop(fd))
18 for fd in write:
19 resume(write_waiters.pop(fd))
20 # something about errors
我们可能希望在上面的代码中增加timeouts,在这种情况下,我们可能会写一些类似下面的代码:
1timeout_waiters = []
2def wait_for_timeout(delay, waiter):
3 when = time.time() + delay
4 heapq.heappush(timeout_waiters, (when, waiter))
5def event_loop():
6 while True:
7 now = time.time()
8 read, write, error = select.select(
9 rfds, wfds, efds,
10 timeout_waiters[0][0] - time.time()
11 )
12 while timeout_waiters:
13 if timeout_waiters[0][0] <= now:
14 _, waiter = heapq.heappop(timeout_waiters)
15 resume(waiter)
所有的异步I/O框架都是建立在同样的模型之上.只是采用了不同的方式构建代码.这样,当发出I/O操作请求的时候,可以暂停;当这个操作完成的时候,又可以恢复.
四、回调
例子:
1Javascript/Node
2Tornado IOStream
3Twisted Deferred
4asyncio, under the hood
有一种方式是,当有数据可读的时候,只是调用一个可调用的函数. 通常,我们希望在更高层面去做处理,而不仅仅只是处理一块一块的数据.于是,我们用一个回调函数读取和分析二进制数据块,当分析数据内容的过程完成后,调用应用程序的回调函数(例如HTTP请求或是应答).
用户代码看起来像下面这样:
1def start_beer_request():
2 http.get('/api/beer', handle_response)
3def handle_response(resp):
4 beer = load_beer(resp.json)
5 do_something(beer)
我们如何才能把响应和特定的请求关联起来呢?一种方式是使用闭包:
1def get_fruit(beer_id, callback):
2 def handle_response(resp):
3 beer = load_beer(resp.json)
4 callback(beer)
5 http.get('/api/beer/%d' % beer_id, handle_response)
这两种方式都比较丑陋,特别是当我们需要关联更多的I/O调用的时候(有人喜欢这种更深层的嵌套吗?).这将会无法逃脱嵌套以及碎片化的编程.就像人们常说的,”回调就是新的GOTO语句”.
回调堆栈看起来像这样:
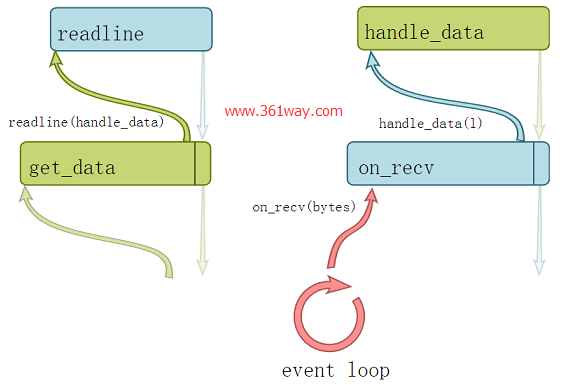
注意,返回值别无用处,视觉上,唯一的传递结果的方式是编写额外的回调函数.
基于方法的回调
例子:
1Twisted Protocols
2Tornado RequestHandler
3asyncio Transports/Protocols
回调简直是一团糟!但是我们可以将回调组织成接口,而这些接口的函数则自动注册为回调,这样,使用者只要继承接口去实现即可.例如,asyncio的示例代码:
1import asyncio
2class EchoClient(asyncio.Protocol):
3 message = 'This is the message. It will be echoed.'
4 def connection_made(self, transport):
5 transport.write(self.message.encode())
6 print('data sent: {}'.format(self.message))
7 def data_received(self, data):
8 print('data received: {}'.format(data.decode()))
9 def connection_lost(self, exc):
10 print('server closed the connection')
11 asyncio.get_event_loop().stop()
这种方式并没有解决消除回调的问题,而只是提供了一种更为简洁的框架,去避免回调散布在代码的各个地方.它设置了对回调怎么调用以及在哪里定义的限制.假设,你希望把两种协议连接起来,例如,你在处理一个来自用户的请求过程中,需要将一个HTTP请求发送至后端的REST服务.这时,你就会碰到多个回调在逻辑上碎片化的问题.同时,你也无法使用异步函数的返回值.
回调中的错误处理
当使用一个基于回调的编程模型的时候,你不得不注册额外的错误处理回调函数.可惜的是,不是所有的框架都强化这一点.一个原因是,如果强化的话,将会使每个单独的程序晦涩难懂.于是,它是一个可选项.结果是,程序员并不是总是会(甚至经常不)这样做。这违反了 PEP20:错误应该显示的传递,除非被显示的忽略了.
没有合理的处理错误的一个较大的风险是,程序内部状态不再是同步的状态,可能会因为等待永远不会触发的事件而死锁,或者是无限的保留一个已经断开的连接的资源.
五、基于生成器的协程
示例:
1tornado.gen
2asyncio/Tulip
生成器已经被用作实现类似协程的功能.它允许我们在某个事件循环系统中,在I/O操作完成后,恢复回调之后的代码块.
1import asyncio
2@asyncio.coroutine
3def compute(x, y):
4 print("Compute %s + %s ..." % (x, y))
5 yield from asyncio.sleep(1.0)
6 return x + y
7@asyncio.coroutine
8def print_sum(x, y):
9 result = yield from compute(x, y)
10 print("%s + %s = %s" % (x, y, result))
11loop = asyncio.get_event_loop()
12loop.run_until_complete(print_sum(1, 2))
13loop.close()
(在这个例子中,需要指出的是,通过这种办法,我们希望产生其他的同步操作,以便获取一些规模效应的好处).在PEP255中介绍生成器的时候,它们被描述为可提供类似协程的功能.PEP342和PEP380拓展了这种能力,在给生成器发送异常的同时,也可以让子生成器产生迭代.
术语”协程”意味着多于一个常规程序的系统.实际上,调用栈每次调用活跃一次.因为每个调用栈是被保留的,一个常规程序可以暂停它的状态,然后转换到一个不同的协程.在一些编程语言中,有一个yield关键字,某些方式上表现出这样的效果(和Python里面的yield关键字差别很大).
为什么你希望这么做呢?它提供了一种原始形态的多任务–合作的多任务.不像线程,它们不是抢占式的.这意味着它们不会被中断(抢占),直到显示的调用了yield.生成器是这种行为的子集,正好契合’yield’术语.维基百科成它们是半协程.然而,生成器和协程有两个重要的不同点:
1.生成器只能迭代到调用帧
2.在迭代到调用帧的时候,栈里面的每一帧都需要协作.顶部帧可能迭代,栈里面的其他调用也来自yield.
这个调用栈看起来像下面这样:
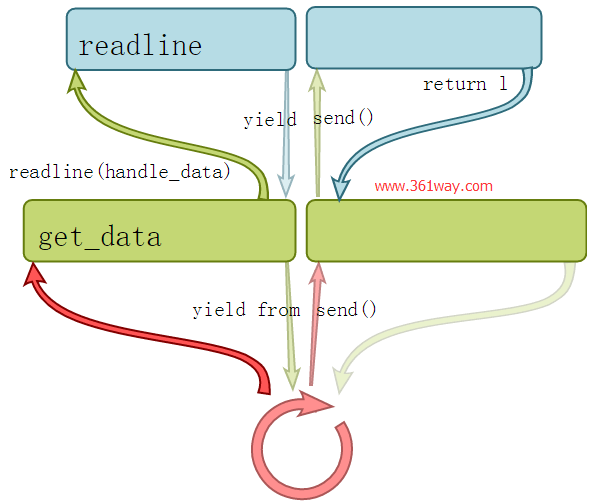
需要指出的是,这种使用yield的方式意味着,你不能使用yield编写异步生成器,而必须返回列表.
六、Greenlets/green threads
一个greenlet是一个完整的协程.
例子:
– gevent
– greenlet
– Stackless Python
让我们用gevent重写异步I/O的例子:
1import gevent
2def compute(x, y):
3 print "Compute %s + %s ..." % (x, y)
4 gevent.sleep(1.0)
5 return x + y
6def print_sum(x, y):
7 result = compute(x, y)
8 print "%s + %s = %s" % (x, y, result)
9print_sum(1, 2)
(同样的,通过这种方法,我们将启动其他的greenlet以获得规模效应的优势).这个例子更加简单了!我们可以简单的忽略所有的生成器不一致的地方,因为gevent.sleep()可以触发事件循环(在gevent称作hub),而不需要引入调用帧.同样的,因为我们有顶层的协程,hub可以在需要时实例化,它不需要被创建为栈的显式的父类.
协程提供了从当前栈跳到事件循环,以及从事件循环返回当前栈的神奇功能

上面C语言级别的代码,允许我们编写看起来是同步的,但实际上却所有拥有异步I/O特性的代码.
七、Gevent: greenlets 和 monkey-patching
我们的代码里要假定没用sleep? 我们可以用gevent的猴子补丁来确保不需要更改代码:
1# These two lines have to be the first thing in your program, before
2# anything else is imported
3from gevent.monkey import patch_all
4patch_all()
5import time
6def compute(x, y):
7 print "Compute %s + %s ..." % (x, y)
8 time.sleep(1.0)
9 return x + y
10def print_sum(x, y):
11 result = compute(x, y)
12 print "%s + %s = %s" % (x, y, result)
13print_sum(1, 2)
标准库中的大部分阻塞调用都会被打补丁,这样可以用hub调度而不必堵塞。同样的,线程系统会用微线程代替线程。
monkey-patching很糟糕吗?
在这种情况下,最好把gevent当做python的一部分,它使用了green thread,然后包含标准库代码的不同实现.部分原因是,它必须在包含程序入口的模块的最开头.它是在代码运行前,我们使用gevent版本stdlib的一个声明.monkey patching是优雅的,它允许纯Python应用程序和库在不做修改的情况下变成异步的.它是gevent的一个可选组件,不需要它也可以编写异步程序.
- 它可以和已存在的同步纯Python代码一起运行
- 一般也可以和异步代码一起运行,只模拟过select(),但是大多数异步框架都有一个基于select()的实现,像epoll()等函数也是可以实现的.
gevents线程原语的例子
因为gevent是基于轻量级的”线程”,所以gevent库包含大量的并发工具来生成greenlet,实现临界区(锁和互斥变量)以及在greenlet之间传递消息.因为它是一个网路库,所以也包含了一些高级别的网路服务模块,如TCP服务器和WSGI服务器.
生成和杀死greenlets
- gevent.spawn(function, *args, **kwargs) – 生成greenlet
- gevent.kill(greenlet, exception=GreenletExit) – 杀死greenlet是通过在greenlet里面引发异常.
这里也有一些高级别的原语,像gevent.pool,它基于greenlet,与multiprocessing.pool对等.
同步原语
gevent.lock.Sempahore
gevent.lock.RLock
gevent.event.Event
消息传递
gevent.queue.Queue
gevent.event.AsyncResult – 等待单一结果而阻塞,也允许引发异常.
超时
这里有一个有用的包装器,可以用来杀死一个段时间内都没有成功运行的greenlet.它可以用来在其他一系列操作中引入超时.
1from gevent import Timeout
2with Timeout(5):
3 data = sock.recv()
更高级别的服务器工具
gevent.server.StreamServer – TCP服务器,同时也支持SSL.
gevent.server.DatagramServer – UDP服务器.
gevent.pywsgi.WSGIServer – WSGI服务器,支持流,保持存活和SSL等.
Gevent I/O模式
使用gevent (避免使用select())时,推荐为各个方面的交互生成一个greenlet–包括读和写.每个greenlet的代码只是一个简单的循环,在需要时可以阻塞.查看早前的chat server 的代码作为示例.
八、为什么我们想要一个同步的编程模型?
首先,它让代码更易懂易读.它和单线程是一样的编程方式.使用yield后代码不会分散.
更重要的是,上面描述的这些方法,只有gevent不需要改变代码的调用约定.这个重要性不应该被低估,它意味着业务逻辑代码可以通畅的进入到阻塞代码.
一个简单的例子,假设我们想开发一个流式API,之前存在的业务逻辑代码(process_orders)需要一个迭代器.通过gevent,和远程服务器交互过程中,我们可以异步的流化迭代器,而不需要修改代码.
1from gevent.socket import create_connection
2def process_orders(lines):
3 """Do something important with an iterable of lines."""
4 for l in lines:
5 ...
6# Create an asynchronous file-like object with gevent
7socket = create_connection((host, port))
8f = socket.makefile(mode='r')
9process_orders(f)
另一个优势是,在敏感的地方总可以引发异常.
和真实的线程不同,greenlet不会在任意时间暂停,于是可以使用更少的锁和互斥量.只是在原子操作过程中存在阻塞的风险的时候,需要一个互斥量.
和真实线程的另一个不同是,一个greenlet可以杀死另外一个greenlet–当greenlet下一次恢复的时候触发一个异常.
缺点
坏消息:Python 3分支版本的gevent还没有开发完成.我暂未查明是否它根本不可用.
异步I/O的缺陷
和其他异步I/O框架一样,gevent也有一些缺陷:
- 阻塞(真正的阻塞,在内核级别)在程序中的某个地方停止了所有的东西.这很像C代码中monkey patch没有生效.你需要采用更细致的方法让C代码库”green”.
- 保持CPU处于繁忙状态.greenlet不是抢占式的,这可能导致其他greenlet不会被调度.
- 在greenlet之间存在死锁的可能.
总的来说,相对于其他异步I/O框架,gevent的缺陷更少(当然,你可能不能死锁回调,这仅仅是因为,事件循环没有提供同步原始,所以你无法实现临界区).一个gevent回避的缺陷是,你几乎不会碰到一个和异步无关的Python库–它将阻塞你的应用程序,因为纯Python库使用的是monkey patch的stdlib.
n到m的并发
对于事件而言,一种更具规模效应的方法是,在m个物理线程中运行n个greenlet.在Python中,我们需要进程来做到这点.在多核系统中,这增加了性能,也增加了灵活性。这是Rust和Java在其他地方使用的模型.
九、使用gevent的经验
我评估过gevent以及在2011提到的其他系统.Gevent无疑是胜者.虽然在性能上面没太多选择,但是gevent简化编程模型却是一个主要的卖点.不是所有的开发者,在使用生成器,闭包和回调函数的时候都处于相同的水平.但是gevent没有这个要求,你可以使用任何技术让代码更易读.
在已有的代码或与I/O无关的业务逻辑中使用gevent也是很有价值的:你可能希望,在高性能的网络应用程序和线下的批处理进程中重用某个业务逻辑库.
在接下来的18个月里面,我一直在写各种各样的网络应用程序.一个产品是名为nucleon的web服务框架,它的目标是连接RESTful JSON,PostgreSQL和AMQP,所有的都通过”绿色”驱动代码保持高伸缩性.
尽管我们需要修改代码,以非阻塞的方式使用PostgreSQL,但是gevent的mokey patching意味着纯Python驱动在其他数据存储过程中已经正常运行了–所以Redis,ElasticSearch和CouchDB都可以透明的使用.
AMQP库最初是Puka (不是Pika)的一个复制, AMQP库没有强化异步的特性(像Pika一样).我最终完全重写了它,并把它单独作为一个名为nucleon.amqp的项目. nucleon.amqp允许使用完整的同步编程模型和AMQP服务器交互–AMQP的远程队列可以通过Queue API暴露在本地.
在一些并发编程的项目中,也有一些让人抓狂的时候.但是作为一个团队,我们适应了gevent,并且开发了一种图表语言.用它来向各个成员解释,理解各个greenlet之间的数据流向,相互之间如何阻塞以及如何发送信号.
这个项目成功了.我们保持代码简洁和可维护,同时也保证服务高效和可伸缩(负载测试中保留的)
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/python-gevent/5329.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.