SSD优化案例:读策略优化和中断多核绑定
IO优化除了磁盘选型、RAID级别设定等因素外,在kernel层也有IO调度与CPU中断可以优化。在RH442之linux IO调度(电梯算法)篇中提到了IO算法的选择与优化,而在无意间刚好看到了小米运维部站点上的一篇文章,也提到了一篇关于和IO优化相关的文章,这里摘录过来。也为RH442下一篇CPU中断总结部分做一个承上启下。
没有开场白,直接切主题!各位把这篇当成是报告来阅读吧:
**应用IO模型:**大量读线程同时访问多块SSD,请求均为4KB随机读,并且被请求的数据有一定间隔连续性;
**服务器硬件配置:**LSI SAS 2308直连卡 + 8块SSD
优化前应用QPS:27K
第一轮优化:读策略优化
通过 /sys/block/sdx/queue/read_ahead_kb 观察到预读大小为128KB,进一步观察iostat情况:
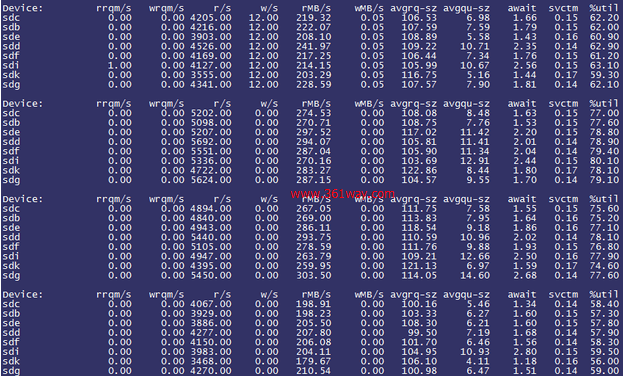
观察到每块SSD的rMB/s十分高,平均已经达到了250MB/s+,初步判断是由于read_ahead_kb的设置影响了应用的读效率(即预先读取了过多不必要的数据)。遂将read_ahead_kb设置为0,观察iostat情况如下:
而应用QPS却下降至25K!
分析原因:由于之前有预读功能存在,因此部分数据已经被预先读取而减轻了SSD的访问压力。将read_ahead_kb设置为0后,所有的读访问 均通过随机读实现,一定程度上加重了SSD的访问压力(可以观察到之前%util大约在60~80%之间波动,而预读改成0之后%util则在 80~90%之间波动)
尝试16K预读
通过IO模型了解到每次请求的数据大小为4KB,因此将read_ahead_kb设置为16KB进行尝试,结果QPS由25K猛增到34K!
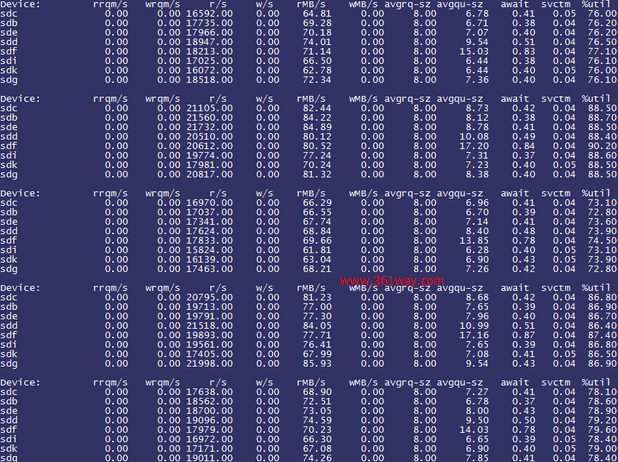
观察iostat情况如下:

%util降了不少,而且通过rrqm/s可以发现出现了一部分读合并的请求,这说明优化确有成效。
此时CPU_WA也由原来的平均30%下降到20%,这说明处理器等待IO的时间减少了,进一步验证了IO优化的有效性。
第二轮优化:直连卡中断多核绑定
考虑到SSD的随机读写能力较强(通过上面的iostat可以发现),在多盘环境下每秒产生的IO请求数也已接近100K,了解到LSI SAS 2308芯片的IOPs处理极限大约在250K左右,因此判断直连卡控制芯片本身并不存在瓶颈。
其实我们担心更多的是如此大量的IO请求数必定会产生庞大数量的中断请求,如果中断请求全部落在处理器的一个核心上,可能会对单核造成较高的压力, 甚至将单核压力打死。因此单核的中断请求的处理能力就有可能成为整个IO系统的瓶颈所在,于是我们通过mpstat观察每个核心上的中断数:
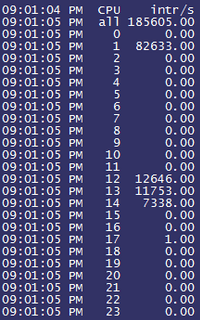
可以发现第二个核心中断数已经达到了十分恐怖的80K!再来观察实际的处理器核心压力情况,为了能够更加直观地了解,我们用了比较准确的i7z工具来观察---i7z是适用于i7\i5\i3处理器的report工具,看来小米的该项测试也是在PC上测试的:
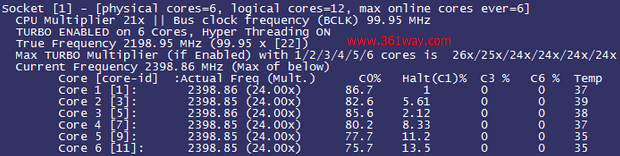
果然不出所料,Core 1的Halt(idle)已经到了1,充分说明第二个核心确实已经满载。那么通过观察/proc/interrupt的情况再来进一步验证我们的假设,:

我们截取了片段,可以发现mpt2sas0-misx的大部分压力都集中在了CPU 1上,并且我们发现直连卡模式是支持多队列的(注意观察irq号从107至122,mpt2sas驱动总共有16个中断号),因此我们将实际在处理中断的 irq号107至118分别绑定至不同的核心上(这里就不再赘述有关多核绑定的原理,有兴趣的同学可以百度搜索以上命令的含义):
随后我们惊奇地观察到应用的QPS由34K再次猛增至39K!通过观察mpstat发现大量的中断被平均分散到了不同的处理器核心上:

并且CPU_WA也由平均20%下降到15%,io wait被进一步优化!
优化总结:
- 通过以上两个优化方法将应用的QPS由27K优化至39K,并且处理器的iowait由30%下降至15%,优化收效显著;
- SSD的优化要根据实际的应用IO模型和设备的理论极限值进行综合考虑,同时还要考虑到各个层面的瓶颈(包括内核、IO策略、磁盘接口速率、连接控制芯片等)。
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/ssd-cpu-interrupts/4898.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.