linux uptime和系统负载
linux uptime命令用于显示系统已经运行了多长时间,它依次显示下列信息:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。我们平进主机关心的是load average的结果。(除了uptime命令,w和top命令也有load average的结果输出。)这个输出结果主要是和CPU的使用情况相关的。然而如何衡量得出的结果是否是负载过高呢?
网上很多文章给予的答复是:
- 如果每个CPU内核的当前活动进程数不大于3的话,那么系统的性能是良好的;
- 如果当前活动进程数不大于4,表示可以接受;
- 如果每个CPU内核的任务数大于5,那么这台机器的性能有严重问题。
上面的提到的任务数又是如何计算的呢?
1[root@back ~]# uptime
2 16:54:36 up 82 days, 53 min, 3 users, load average: 1.02, 1.37, 1.90
上面是我的一台linux主机的负载情况。而假如我有两个CPU的话,则每个CPU的任务数就是1.90/2=0.95,这表示该系统的性能是可以接受的。而如查我的是两个四核CPU的话,就应该按8个CPU数来算,即为1.90/8=0.2375,这表明当前的负载是比较的低的。
为了理解load average的概念,我在网上看到过一篇国外译来的文章如下:
你可能对于 Linux 的负载均值(load averages)已有了充分的了解。负载均值在 uptime 或者 top 命令中可以看到,它们可能会显示成这个样子: load average: 0.09, 0.05, 0.01
很多人会这样理解负载均值:三个数分别代表不同时间段的系统平均负载(一分钟、五 分钟、以及十五分钟),它们的数字当然是越小越好。数字越高,说明服务器的负载越 大,这也可能是服务器出现某种问题的信号。
而事实不完全如此,是什么因素构成了负载均值的大小,以及如何区分它们目前的状况是 「好」还是「糟糕」?什么时候应该注意哪些不正常的数值?
回答这些问题之前,首先需要了解下这些数值背后的些知识。我们先用最简单的例子说明, 一台只配备一块单核处理器的服务器。
行车过桥
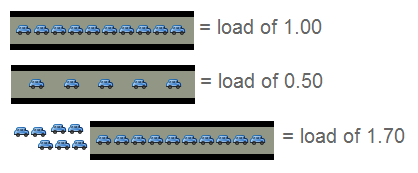
一只单核的处理器可以形象得比喻成一条单车道。设想下,你现在需要收取这条道路的过桥 费 — 忙于处理那些将要过桥的车辆。你首先当然需要了解些信息,例如车辆的载重、以及 还有多少车辆正在等待过桥。如果前面没有车辆在等待,那么你可以告诉后面的司机通过。 如果车辆众多,那么需要告知他们可能需要稍等一会。
因此,需要些特定的代号表示目前的车流情况,例如:
- 0.00 表示目前桥面上没有任何的车流。 实际上这种情况与 0.00 和 1.00 之间是相同的,总而言之很通畅,过往的车辆可以丝毫不用等待的通过。
- 1.00 表示刚好是在这座桥的承受范围内。 这种情况不算糟糕,只是车流会有些堵,不过这种情况可能会造成交通越来越慢。
- 超过 1.00,那么说明这座桥已经超出负荷,交通严重的拥堵。 那么情况有多糟糕? 例如 2.00 的情况说明车流已经超出了桥所能承受的一倍,那么将有多余过桥一倍的车辆正在焦急的等待。3.00 的话情况就更不妙了,说明这座桥基本上已经快承受不了,还有超出桥负载两倍多的车辆正在等待。

上面的情况和处理器的负载情况非常相似。一辆汽车的过桥时间就好比是处理器处理某线程 的实际时间。Unix 系统定义的进程运行时长为所有处理器内核的处理时间加上线程 在队列中等待的时间。
和收过桥费的管理员一样,你当然希望你的汽车(操作)不会被焦急的等待。所以,理想状态 下,都希望负载平均值小于 1.00 。当然不排除部分峰值会超过 1.00,但长此以往保持这 个状态,就说明会有问题,这时候你应该会很焦急。
「所以你说的理想负荷为 1.00 ?」嗯,这种情况其实并不完全正确。负荷 1.00 说明系统已经没有剩余的资源了。在实际情况中 ,有经验的系统管理员都会将这条线划在 0.70:
- 「需要进行调查法则」:* 如果长期你的系统负载在 0.70 上下,那么你需要在事情变得更糟糕之前,花些时间了解其原因。
- 「现在就要修复法则」:1.00 。* 如果你的服务器系统负载长期徘徊于 1.00,那么就应该马上解决这个问题。否则,你将半夜接到你上司的电话,这可不是件令人愉快的事情。
- 「凌晨三点半锻炼身体法则」:5.00。* 如果你的服务器负载超过了 5.00 这个数字,那么你将失去你的睡眠,还得在会议中说明这情况发生的原因,总之千万不要让它发生。
而对于其内部的计算方法,维基百科也给出了结果:其具体的计算方法是:
 ,
,
其中,
 是上线率,
是上线率,
 是上线时间,
是上线时间,
 是总时间区间。和上线时间相比,上线率往往能够更加直观的表现出系统的稳定程度来。
是总时间区间。和上线时间相比,上线率往往能够更加直观的表现出系统的稳定程度来。
除此这外,要查看地系统的负荷我们还要和top及vmstat得出的id空闲值和procs 的r值进行比对查看。
注:top执行后,按1就可以看到每个CPU的利用率了。
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/uptime/1436.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.