wkhtmltopdf html转pdf工具的使用
wktmltopdf 工具是使用Webkit引擎来将HTML网页转换为PDF文件。其可以将一个URL对应的网页转换为HTML,也可以将存在本地的一个html 文件转换为 pdf 文件。其在应用中有两个优势:
1、该软件是开源免费软件;
2、该软件支持linux\windows\macos 这些常用的平台。
一、安装
这里以windows为例(本想在 linux 下测试,但在中文时乱码,需要安装对应的中文字库),打开 https://github.com/wkhtmltopdf/wkhtmltopdf/releases/ 地址下载最新版本。直接下一步下一步即可,安装完成后,想在直接CMD下键入命令就可以使用,还需要配置环境变量:
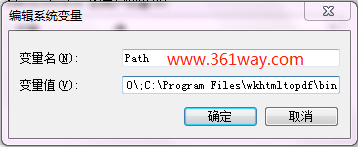
二、测试使用
在CMD命令行下,可以使用如下命令进行测试:
1wkhtmltopdf https://www.baidu.com/ D:\baidu.pdf //网络页面
2wkhtmltopdf test.html test.pdf //本地HTML页面
3# 指定源html编码为utf8,并给转换后的pdf文件加上页眉页脚信息
4wkhtmltopdf --encoding utf8 --header-center 访问www.361way.com获取更多信息 --footer-center email至[email protected]交流 test.html out.pdf
批量转换
这个是针对单个文件的,我使用python采集了一批html 页面,想全部转换为HTML也很方便,这里使用了下powershell 代码:
1Get-ChildItem *.html |ForEach-Object -Process{
2 $newname=($_.name.Split(".")[0] + '.pdf');
3 wkhtmltopdf --encoding utf8 --header-center 访问www.361way.com获取更多信息 --footer-center email至[email protected]交流 $_.name $newname
4}
虽然很快,不过还是吐槽下powershell 语法很烂,和python的可读性相比,差太多了。当时也是有点脑抽,想到使用powershell 实现批量,哈哈!
三、关于乱码问题
出现乱码问题,一般是两种可能:一、是字体库不存在该可用的字体;一种是编码不对。一般后者比较多。字体不在这个就没什么好说的了,安装下字体就行了。看编码不对的问题,可以通过如下两种方法解决:
1、在html 指定编码
我采集下来的html 文件,去掉了很多无用的内容,所以不包含编码信息,这里在第一行加入如下内容:
<pre data-language="HTML">```markup
<meta http-equiv="content-type" content="text/html;charset=utf-8">
注意,这里一定要是第一行,我尝试加到后面,发现仍会乱码。
#### 2、指定参数
wkhtmltopdf工具本身,有提供–encoding 参数,在该参数后面,指定对应的编码即可。
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/wkhtmltopdf/5703.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.