clickhouse(一)单节点安装使用
一、clickhouse概述
clickhouse是Yandex(俄罗斯版的百度)于 2016 年开源的一个用于联机分析(OLAP)的列式大数据库管理系统(DBMS)。常见的很多人会将其和Druid、ES、Pinot等库进行对比。由于其具有低延迟、高写入速度、磁盘空间占用低等特点,同时几乎和mysql一样的查询语法。实际学习使用的门槛比较低。其具备以下特性:
- 采用列式存储
- 数据压缩
- 基于磁盘的存储,大部分列式存储数据库为了追求速度,会将数据直接写入内存,按时内存的空间往往很小
- CPU利用率高,在计算时会使用机器上的所有CPU资源
- 支持分片,并且同一个计算任务会在不同分片上并行执行,计算完成后会将结果汇总
- 支持SQL,SQL几乎成了大数据的标准工具,使用门槛较低
- 支持联表查询
- 支持实时更新
- 自动多副本同步
- 支持索引
- 分布式存储查询
二、单机安装ClickHouse
ClickHouse支持在线安装、离线安装、源代码编译安装、Docker镜像安装。这里使用yum源在线单机版安装测试。安装时可以使用https://repo.clickhouse.tech/rpm/stable/x86_64 或 https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/源。在centos7/centos8上的安装方式如下:
1yum install yum-utils
2rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
3yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/clickhouse.repo
4yum install clickhouse-server clickhouse-client
安装后会自动创建clickhouse帐号,安装完成后,其默认的重要文件和目录如下:
1# 服务端配置
2/etc/clickhouse-server
3 config.xml # 全局配置文件
4 user.xml # 用户配置文件
5# 客户端配置
6/etc/clickhouse-client
7 config.xml # 客户端配置文件
8# ClickHouse文件句柄数配置
9/etc/security/limits.d/clickhouse.conf
10# 默认值262144,应该足够了
11clickhouse soft nofile 262144
12clickhouse hard nofile 262144
13# ClickHouse全局配置文件: /etc/clickhouse-server/config.xml
14# 默认数据存储目录(一般需要修改为大容量磁盘挂载的目录)
15/var/lib/clickhouse
16# 默认日志存储目录(一般需要修改为大容量磁盘挂载的目录)
17/var/log/clickhouse-server
如果要修改默认的数据存储目录,可以通过方式修改:
1# 创建数据目录并授权
2mkdir -p /chbase/data/
3chown -R clickhouse.clickhouse /chbase/data/
4# 修改/etc/clickhouse-server/config.xml
5<path>/chbase/data/</path>
6<tmp_path>/chbase/data/tmp/</tmp_path>
7<user_files_path>/chbase/data/user_files/</user_files_path>
日志文件存在/var/log/clickhouse-server目录,同样也可以修改config.xml文件修改,其默认配置如下:
1<level>trace</level>
2<log>/var/log/clickhouse-server/clickhouse-server.log</log>
3<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
4<size>1000M</size>
5<count>10</count>
以服务方式启动:
1systemctl enable clickhouse-server
2systemctl start clickhouse-server
三、连接测试
下载官方测试数据,进行测试,解压路径以实际存储路径为准,按照上面的配置文件修改示例,需要解压到/chbase/data目录。测试部分数据可以官方在线帮助文档。
1curl -O https://datasets.clickhouse.tech/hits/partitions/hits_v1.tar
2tar xvf hits_v1.tar -C /var/lib/clickhouse
3curl -O https://datasets.clickhouse.tech/visits/partitions/visits_v1.tar
4tar xvf visits_v1.tar -C /var/lib/clickhouse
5systemctl restart clickhouse-server
可以使用clickhouse-client进行sql连接,查询方式如下:
1# 直接查询
2[root@361way ~]# clickhouse-client --query "SELECT * FROM datasets.hits_v1 limit 10000";
3# 交互式查询
4361way :) show databases;
5SHOW DATABASES
6Query id: dfd99b12-40af-42aa-9032-3213623fa7d5
7┌─name─────┐
8│ datasets │
9│ default │
10│ system │
11└──────────┘
123 rows in set. Elapsed: 0.001 sec.
13# http restful接口查询
14[root@361way ~]# curl -X POST http://127.0.0.1:8123 -d "SELECT COUNT(*) FROM datasets.hits_v1"
158873898
16[root@361way ~]# curl http://127.0.0.1:8123 -d "SELECT COUNT(*) FROM datasets.hits_v1"
178873898
18# 导入csv数据
19[root@361way ~]# clickhouse-client -h 192.168.1.17 --query="insert into database.table FORMAT CSV" < /opt/data.csv
20# 导出为csv数据
21[root@361way ~]# clickhouse-client --query="select * from database.table FORMAT CSV" > /opt/data.csv
注:通过http接口进行查询进同时支持get、post请求,不过进行修改和创建操作只能通过post方法。
从简单的测试来看,其性能还是比较逆天的,以下是我在8c、16G的一台普通云主机上测试的结果,表结构181个字段,查询500万行数据并导出耗时1分钟不到(导出4.6G的csv数据)。
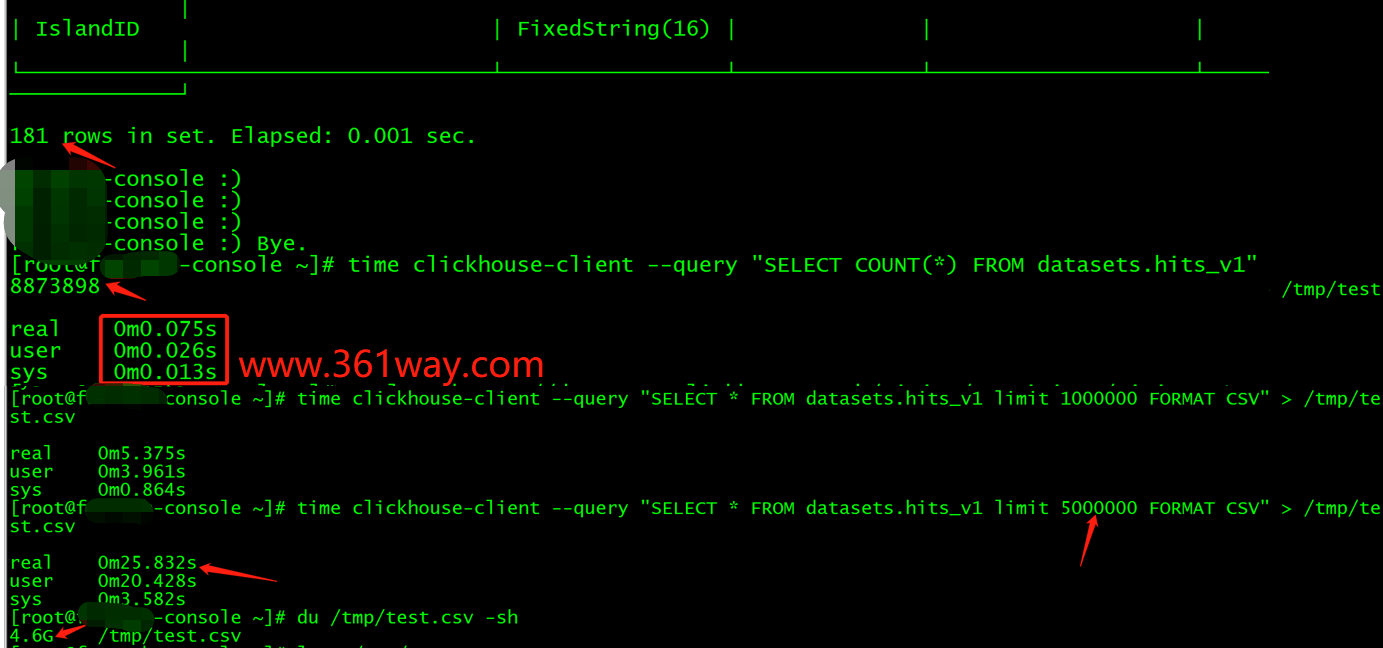
总结:
性能数据:
- 低延迟:对于数据量(几千行,列不是很多)不是很大的短查询,如果数据已经被载入缓存,且使用主码,延迟在50MS左右;
- 并发量:虽然ClickHouse是一种在线分析型数据库,也可支持一定的并发。当单个查询比较短时,官方建议100 Queries / second;
- 写入速度:在使用MergeTree引擎的情况下,写入速度大概是50 - 200M / s,如果按照1 K一条记录来算,大约每秒可写入50000 ~ 200000条记录每秒。如果每条记录比较小的话写入速度会更快;
常见应用场景:
- 电信行业用于存储数据和统计数据使用;
- 新浪微博用于用户行为数据记录和分析工作;
- 用于广告网络和RTB,电子商务的用户行为分析;
- 日志分析;
- 检测和遥感信息的挖掘;
- 商业智能;
- 网络游戏以及物联网的数据处理和价值数据分析;
- 最大的应用来自于Yandex的统计分析服务Yandex.Metri ca。
不足:
- 不支持事务、异步删除与更新
- 不适用高并发场景
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/clickhouse/6609.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.