pandas if条件判断
python pandas模块是一个功能强大的DataFrame数据处理模块,这里就是结果几个具体常见的应用场景来展示下其应用,该处展示的功能excel上也可以实现,不过站在一个懂python的人角度来说,我觉得这种处理方法比excel更高效好玩。
一、数字判断
这里实现的功能比较简单,根据一列数据生成另一列数据,比如,我们给出一列数据1-10,其中大于4的判断为False,小于等于4的设置为True。操作语法如下:
1df.loc[df['column name'] condition, 'new column name'] = 'value if condition is met'
完整示例代码:
1from pandas import DataFrame
2numbers = {'set_of_numbers': [1,2,3,4,5,6,7,8,9,10]}
3df = DataFrame(numbers,columns=['set_of_numbers'])
4df.loc[df['set_of_numbers'] <= 4, 'equal_or_lower_than_4?'] = 'True'
5df.loc[df['set_of_numbers'] > 4, 'equal_or_lower_than_4?'] = 'False'
6print (df)
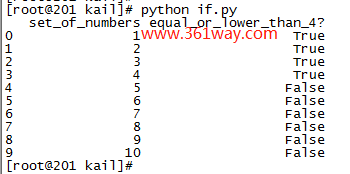
输出结果如下:
二、lambda数字判断
上面的示例比较好理解,直接通过值的多次判断给出不同的值,不好的地方在于需要写多个条件,哪有一条搞定的方法。当然有,使用lambda匿名函数,如下:
1df['new column name'] = df['column name'].apply(lambda x: 'value if condition is met' if x condition else 'value if condition is not met')
完整测试代码:
1from pandas import DataFrame
2numbers = {'set_of_numbers': [1,2,3,4,5,6,7,8,9,10]}
3df = DataFrame(numbers,columns=['set_of_numbers'])
4df['equal_or_lower_than_4?'] = df['set_of_numbers'].apply(lambda x: 'True' if x <= 4 else 'False')
5print (df)
上面代码的输出效果和第一种输出是一样的。效率吗,数据量比较小是看不出的,你可以生成一个大列表几十万数据量的列表,分别试下效果看。
三、字符串判断
这里的需求也比较简单,比如一个列表里有多个名字,我们现在想把BILL找出来,是BILL的行显示Match,不叫的BILL的Mismatch 。这个示例就是第一个示例的变种,测试代码如下:
1from pandas import DataFrame
2names = {'First_name': ['Jon','Bill','Maria','Emma']}
3df = DataFrame(names,columns=['First_name'])
4df.loc[df['First_name'] == 'Bill', 'name_match'] = 'Match'
5df.loc[df['First_name'] != 'Bill', 'name_match'] = 'Mismatch'
6print (df)
7# 代码执行后输出如下:
8 First_name name_match
90 Jon Mismatch
101 Bill Match
112 Maria Mismatch
123 Emma Mismatch
同样该问题也可以用lamda解决:
1from pandas import DataFrame
2names = {'First_name': ['Jon','Bill','Maria','Emma']}
3df = DataFrame(names,columns=['First_name'])
4df['name_match'] = df['First_name'].apply(lambda x: 'Match' if x == 'Bill' else 'Mismatch')
5print (df)
四、字符串多重匹配
还是第三部分的示例,假如我想找出BILL和Emma两个人,怎么办呢?是不是要加 or 条件 and 条件判断,具体代码如下:
1from pandas import DataFrame
2names = {'First_name': ['Jon','Bill','Maria','Emma']}
3df = DataFrame(names,columns=['First_name'])
4df.loc[(df['First_name'] == 'Bill') | (df['First_name'] == 'Emma'), 'name_match'] = 'Match'
5df.loc[(df['First_name'] != 'Bill') & (df['First_name'] != 'Emma'), 'name_match'] = 'Mismatch'
6print (df)
7#输出结果如下:
8 First_name name_match
90 Jon Mismatch
101 Bill Match
112 Maria Mismatch
123 Emma Match
五、修改匹配值
经如,我想将某列数据中的5改为555,0改为999,具体代码如下:
1from pandas import DataFrame
2numbers = {'set_of_numbers': [1,2,3,4,5,6,7,8,9,10,0,0]}
3df = DataFrame(numbers,columns=['set_of_numbers'])
4print (df)
5df.loc[df['set_of_numbers'] == 0, 'set_of_numbers'] = 999
6df.loc[df['set_of_numbers'] == 5, 'set_of_numbers'] = 555
7print (df)
效果如下:

同样的,我们还可以把pandas中的Nan数据修改为0,具体代码如下:
1from pandas import DataFrame
2import numpy as np
3numbers = {'set_of_numbers': [1,2,3,4,5,6,7,8,9,10,np.nan,np.nan]}
4df = DataFrame(numbers,columns=['set_of_numbers'])
5print (df)
6df.loc[df['set_of_numbers'].isnull(), 'set_of_numbers'] = 0
7print (df)

捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/if-condition-in-pandas/6362.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.