pandas小结(六)merge数据合并
在《pandas小结(五)concat数据合并》中提到了数据合并,本篇学习另一个数据合并方法merge,不过这个和concat是有区别的,concat方法准确的说更像是级联,而不算合并,merge才是真正意义的合并。merge个人用的比较多的一个场景就是两个pandas数据,有相同的列数据,需要根据相同的列数据进行合并的。
一、merage函数介绍
merage函数的用法如下:
1pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
2left_index=False, right_index=False, sort=True)
其中的参数用法为:
- left – 一个DataFrame对象。
- right – 另一个DataFrame对象。
- on – 列(名称)连接,必须在左和右DataFrame对象中存在(找到)。
- left_on – 左侧DataFrame中的列用作键,可以是列名或长度等于DataFrame长度的数组。
- right_on – 来自右的DataFrame的列作为键,可以是列名或长度等于DataFrame长度的数组。
- left_index – 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 在具有MultiIndex(分层)的DataFrame的情况下,级别的数量必须与来自右DataFrame的连接键的数量相匹配。
- right_index – 与右DataFrame的left_index具有相同的用法。
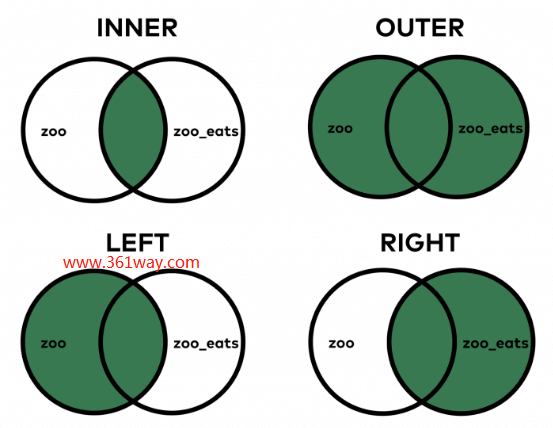
- how – inner(内连接),left(左外连接),right(右外连接),outer(全外连接);默认为inner。
- sort – 按照字典顺序通过连接键对结果DataFrame进行排序。默认为True,设置为False时,在很多情况下大大提高性能。
上面提到的how连接方式,为了便于理解,我们使用SQL语句和pands语句进行下比对。
1、内连接
符合连接条件和查询条件的数据行,相当于数据库中的jion,SQL语句表示如下:
1SELECT * FROM df1 INNER JOIN df2 ON df1.key = df2.key;
2或
3SELECT * FROM df1,df2 where df1.key=df2.key;
4# 对应的pandas语句如下:
5pd.merge(df1, df2, on='key')
2、左外连接
符合连接条件和查询条件的数据行并返回左表中不符合连接条件但符合查询条件的数据行,相当于数据库中的left outer join,示例SQL语句 :
1-- show all records from df1
2SELECT * FROM df1 LEFT OUTER JOIN df2 ON df1.key = df2.key;
3# 对应pandas语句:
4pd.merge(df1, df2, on='key', how='left')
3、右外连接
符合连接条件和查询条件的数据行并返回右表中不符合连接条件单符合查询条件的数据行,相当于数据库中的right outer join,示例SQL语句:
1-- show all records from df2
2SELECT * FROM df1 RIGHT OUTER JOIN df2 ON df1.key = df2.key;
3# 对应pandas语句:
4pd.merge(df1, df2, on='key', how='right')
4、全外连接
符合连接条件和查询条件的数据行并返回左表和左表中不符合连接条件单符合查询条件的数据行。全外连接相当于左外连接与左外连接的合集(去掉重复),相当于数据库中的full outer join,示例SQL语句:
1-- show all records from both tables
2SELECT * FROM df1 FULL OUTER JOIN df2 ON df1.key = df2.key;
3# 对应pandas语句
4pd.merge(df1, df2, on='key', how='outer')
对应图如下:
二、数据合并示例
回到最初的话,这里我给出两个数据,其中有一列的值是唯一,且可以根据该值进行合并的,我们先成后一个测试数据,生成pandas测试数据的方法有如下两种:
1df=DataFrame(columns=['code','prce'])
2df.loc[0]=['002541','40']
3df.loc[1]=['002528','35']
4或
5df = pd.DataFrame([[1, 2], [3, 4]], columns=['code','prce'])
添加数据,也可以append,也可以使用字典的方式进行,如下:
1>>> res = pd.DataFrame(columns=('lib', 'qty1', 'qty2'))
2>>> res = res.append([{'qty1':10.0}], ignore_index=True)
3>>> print(res.head())
4# 输出
5 lib qty1 qty2
60 NaN 10.0 NaN
完整的示例代码如下:
1import pandas as pd
2from pandas import DataFrame
3df=DataFrame(columns=['code','age'])
4df.loc[10]=['002541','40']
5df.loc[11]=['002528','35']
6print(df)
7print("---------------------------------")
8df2 = pd.DataFrame([['002541','小黄狗','100'],['002560','猫咪','60'], ['002528','大飞','80']] , columns=['code','name','price'])
9print(df2)
10print("---------------------------------")
11result = pd.merge(df,df2,left_on='code',right_on='code')
12print(result)
13# 执行结果如下:
14# python merage.py
15 code age
1610 002541 40
1711 002528 35
18---------------------------------
19 code name price
200 002541 小黄狗 100
211 002560 猫咪 60
222 002528 大飞 80
23---------------------------------
24 code age name price
250 002541 40 小黄狗 100
261 002528 35 大飞 80
从上面的输出可以看到,这里默认使用的是内连接,虽然两者之间的index不一值,但通过指定code作为两者连接的依据,两边的值还是匹配在了一起,而且是以第一个df中的数据列为基准。这里因为两边的列名称相同,实际上是可以直接简单为on进行内连接的,其简写类似如下示例:
1import pandas as pd
2left = pd.DataFrame({
3 'id':[1,2,3,4,5],
4 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
5 'subject_id':['sub1','sub2','sub4','sub6','sub5']})
6right = pd.DataFrame(
7 {'id':[1,2,3,4,5],
8 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
9 'subject_id':['sub2','sub4','sub3','sub6','sub5']})
10rs = pd.merge(left,right,on='id')
11print(rs)
当然我们也可以进行更严格的要求,要求两列的值都相同的才进行匹配输出:
1import pandas as pd
2left = pd.DataFrame({
3 'id':[1,2,3,4,5],
4 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
5 'subject_id':['sub1','sub2','sub4','sub6','sub5']})
6right = pd.DataFrame(
7 {'id':[1,2,3,4,5],
8 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
9 'subject_id':['sub2','sub4','sub3','sub6','sub5']})
10rs = pd.merge(left,right,on=['id','subject_id'])
11print(rs)
该示例的输出就只有两行数据,显然是取的两者的交集。显然我们还可以加上how值,同时可以尝试修改how值,查看具体的输出结果:
1import pandas as pd
2left = pd.DataFrame({
3 'id':[1,2,3,4,5],
4 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
5 'subject_id':['sub1','sub2','sub4','sub6','sub5']})
6right = pd.DataFrame(
7 {'id':[1,2,3,4,5],
8 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
9 'subject_id':['sub2','sub4','sub3','sub6','sub5']})
10rs = pd.merge(left, right, on='subject_id', how='left')
11print (rs)
参考页面:pandas官方merge用法页。
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/pandas-merge/6347.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.