SRE运维(九)“面向对象”的监控
一、SRE监控的目标
根据SRE监控的目的不同,可以将监控进行功能性分类,具体如下:
- 在需要人工介入的情况下,发出告警;(对应SLO和健康度打分)
- 调查及诊断这些问题;(根因智鉴)
- 展示有关于系统的可视化信息;(运维大盘或监控大屏)
- 获取有关资源使用率或服务健康度的趋势分析,用于制定长期的规划;(动态阈值分析)
- 比较系统变更前后的行为,或者比较两个实验组的差异。(运维中台+变更或混沌测试)
当然上面的概念听起来估计是比较笼统的,这里我们一步步的来讲。
二、黑盒监控与白盒监控
在讲监控前,我觉得有必要重新梳理下监控的目的。首先弄清楚一个问题,监控是为了什么?性能指标的变化和业务降质、阻断之间是不是一定有必然的关系?
我们来审视下这两个问题:我们在监控系统上配置了很多的监控项,目的是不是为了发现问题?但是CPU、内存、IO等性能指标的变化这个是不是用户所关心的呢?这个要看你提供什么服务对吧,假如我们提供的是一个APP或者一个页面,站在客户的角度来说,客户所关系的应该是我本身访问是不是流畅,页面速度体验是不是和之前一样,这个是不是有点和SLO的理念一致了。所以我们在做监控时,先想到的监控是要重构监控,站在客户的角度完成监控的A面。接下才是B面,技术人员关心的性能告警。这里我们先不谈B面如何做优先,后面的篇幅再讲,我们先做一个总结,监控是不是分为AB两面,这就对应了黑盒监控和白盒监控。
黑盒监控: 通过测试某种外部用户可见的系统行为进行监控。这是面向现象的监控,提供的是正在发生的问题,并向员工发出紧急警报。对于还没有发生,但是即将发生的问题,黑盒监控无能为力。 白盒监控依靠系统内部暴露的一些性能指标进行监控。包括系统性能、日志分析, Java 虚拟机提供的监控接口,或者一个列出内部统计数据的 HTTP 接口进行监控。白盒监控能够通过分析系统内部信息的指标值,可以检测到即将发生的问题。白盒监控有时是面向现象的,有时是面向原因的,这个取决于白盒监控提供的信息。
这里我们完成了监控的拆解(面向用户、面向服务本身)。
三、健康度打分
健康度打分这个是我们内部的一个项目,目的有几个:一是进行告警收敛;二是便于不同技能的on-call人员进行问题判断;三可以达到对架构的拆解审视,换一种新视角看待问题。
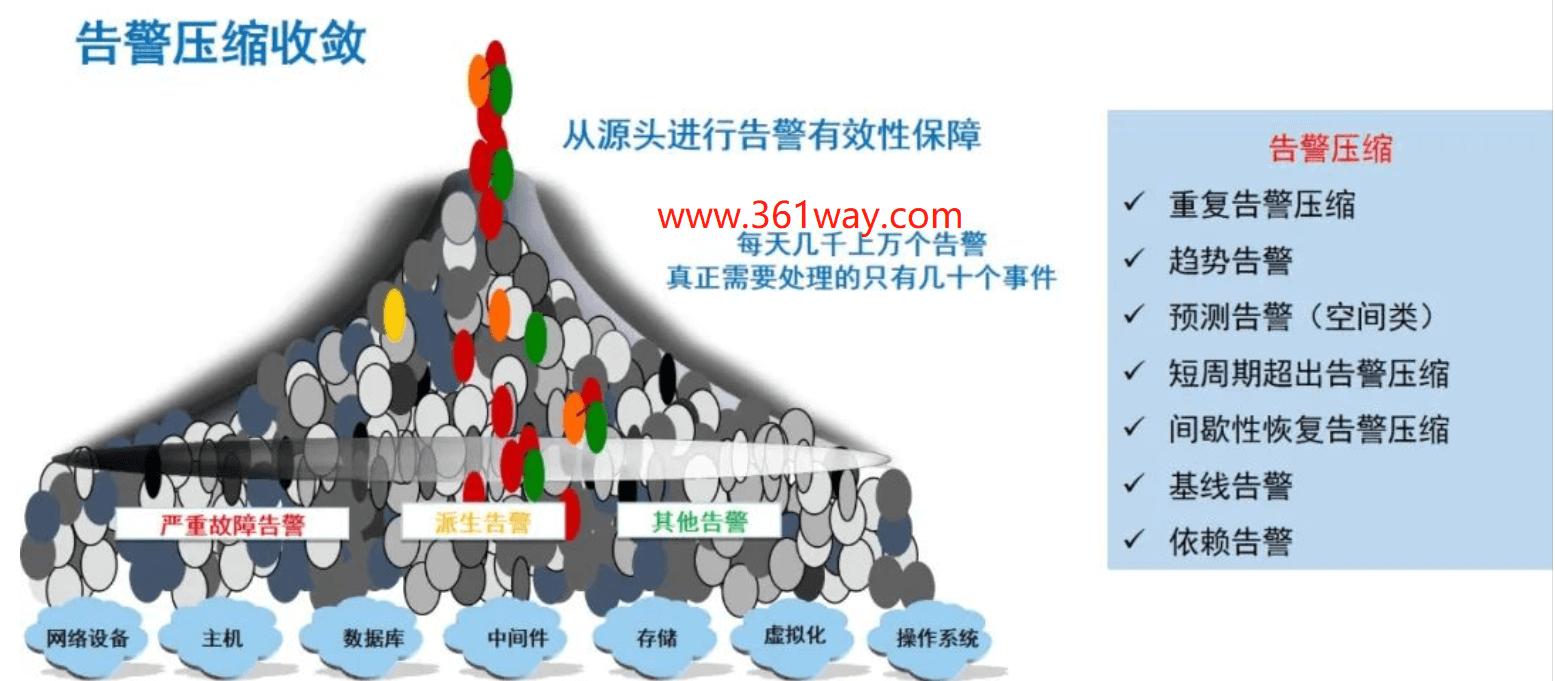
1、架构审视
在一套平台或一套系统拿来的时候首先做的是架构审视,架构审视需要将现有的平台拆分掉架构是什么样的、有多个组件构成、每个组件是几节点、每个节点允许坏几个节点,分别会造成什么现象和影响、在某个组件出现问题的时候,有什么样的应急手段。对于大的平台可能还会有很多细微的拆分方法。这里openstack云平台为例,可以拆分为集群HA、VIM、存储、网络(有时会有SDN/NFV),有些大的块可以再按上面的项进行拆分出组件,有些打这一层就为止了。这样重新审视架构后好处比较多。
- 更好的了解你的平台和架构;
- 为进一步健康度打分(监控优化)打下基础;
- 为on-call人员提供了调度相关的一手文档;
- 为混沌测试提供了一手依据。
2、告警收敛
这部分是健康度打分实现的精髓所在,也是告警收敛的精髓。当前很多企业都部署在云环境下,而且对应的一个应用对应的可能是一组服务器。假设这组服务器对应的一台出现了问题或者性能指标变化,在用户体验层感知没有变化的情况下,我是否一定要出和这台主机相关的一堆的告警呢?因为SRE很多面对的都是一些相对大型的企业,这里我们举个便于理解的例子,在vmware或者openstack环境下,一个HA组里,一台宿主机发生故障,我们是否有必要进行告警通知呢?回到上面的白盒监控和黑盒监控。在白盒监控未发生异常的时候,单机的宿主机故障是无需告警,甚至暂时都可以无需处理这个问题的 —- 原因很简单,业务正常,虚拟机很大可能已正常迁移到其他宿主机,或者再坏点上面的虚拟机也坏了,但是业务自身的HA将业务在其他节点上承载了。这里我们完成了一次告警收敛。
需要注意的,这里不是无限制的让宿主机坏下去,在架构审视阶段,我们已经对HA集群可以坏的节点数进行过模型计算,有了一个最大允许的上限,在没有到达这个上限之前就可以一直坏,但是对于这个坏的承度还是有一个表征方法的。假设我HA集群100%完全好的情况下,这个HA组的得分是100,现在坏了一台宿主机,得分可能变成了95,再坏可能变成了80。针对这个分值我可以设置一个预警线,达到上限的时候比如我是P0级问题,在警戒线的时候可能是p2或p3级问题。好,这里我们完成了一个级别的告警收敛。
接下来我们再换一个维度考虑收敛,上面可能会有人发出这样的疑问,我就是有单机的业务存在,我必须要对这个单节点的情况进行全方位的性能监控。这里我们也举个例子,假设这就是台非常重要的主机(虚拟机或物理机均可),我们平时的监控会把CPU、内存、IO等全部监控下来,但是这样真的合适吗?在长期运维的情况下,我们经常会遇到这样的问题,CPU告警的时候,可能伴随的还有内存使用率、IO使用、load等指标的一起告警。这显然达不到告警聚合压缩的目的,这时候就可以通过一些模型将这些告警进行归并,同时出现的时候,吐出来的只有一条告警。这里又实现了一层告警收敛。
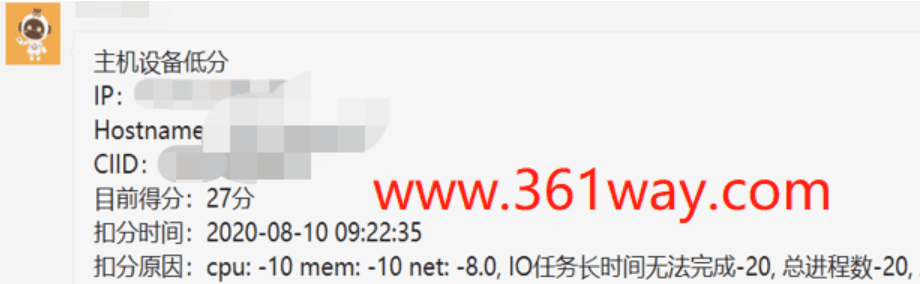
上面提到了白盒监控和黑盒监控,黑盒监控同样也有AB面,一面是面向on-call值班人员的,一面是面向后线团队的。上面提到的监控结果里,是不是还可以再进行一步筛选,这个晒选你可以认定为是面向内部的SLI和SLO,这个我们在前面《SRE运维(五)从SLO开始》里有提到过,比如,阿里向我们提供了dingding这个服务,dingding又构架在阿里云上,阿里云内部又分成了分布式存储团队、云计算架构团队、网络解决方案团队、SRE团队。阿里云SRE的on-call,我不需要关注存储团队的所有指标,我只关注存储面向阿里云这个大应用有感知的几个大指标 —- 没有?可以基于简单的算法或基线参数实现。换个位置思考,如何用1-5个指标表征你整个块能对你的用户最有感知的指标,从果推因,而不是基于全参数这样的因推果。这里讲的就是黑盒监控的A面,实现以后又完成了一层告警收敛。当然黑盒的B面并不是就安全无忧了,A面的指标如果准确率已经够高,能表征98%的指标告警内容了,B面就要去实现面向问题定位和面向跟因智鉴的运维工具或运维手段了。
有了上面提到的三层收敛,我们现在的告警已经较之前变的很少了,同时保证了告警出现后,必是需要界入处理的,这个其实就对应了开头说的第一个告警实现的类型,需要人工介入的情况下,发出告警。当然告警的发出可以有很多种方式,IVR、chatops、工单系统,可以是一个也可以是多个。这个就根据需要进行定制就可以了。
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/object-monitor/6494.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.