Tesseract图文识别与百度AI
标题乍一看有点大,实则拾人牙慧,站在前人已有的成果上略做测试。Tesseract是开源的OCR引擎,作为开源项目发布在Google Project,其项目主页在这里查看 。它支持中文OCR,并提供了一个命令行工具。且对很多编程语言都有支持。百度AI是属于百度的商业产品,上面有人脸、图像、语音等各种识别服务。可以免费测试,一般一天500次调用。超出就要收费了。
一、安装使用
1、开源tesseract安装
1yum-config-manager --add-repo https://download.opensuse.org/repositories/home:/Alexander_Pozdnyakov/CentOS_7/
2yum update
3yum install tesseract
4yum install tesseract-langpack-deu
我使用的是centos对应的包,安装过程中可能会有安装不成功的提示,修改下yum源里对应的gpgcheck=0重试即可。安装完成后,默认自带有英文识别,如果需要进行中文识别,还要单独安装语言库,只有几十M大小,里面是常见汉字的识别码。官方也给出了安装方法:
1Various types of training data can be found on GitHub. Unpack and copy the .
2traineddata file into a 'tessdata' directory.
3The exact directory will depend both on the type of training data, and your Linux distribtion.
4Possibilities are /usr/share/tesseract-ocr/tessdata or /usr/share/tessdata or /usr/share/tesseract-ocr/4.00/tessdata.
字体库文件在:https://github.com/tesseract-ocr/tessdata 地址可以下载。
由于这里直接使用的命令方式测试,并使用第三方语言如python等进行调用。所以未安装pytesseract、pyocr等相关包。
2、百度AI图像识别
这个比较简单,我用的python的类库。在 页有调用文档。下载aip-python-sdk文件,解压后直接python setup install即可,也可以通过pip进行安装。
二、使用测试
1、英文识别
源文件如下(就是tesseract项目上的wiki文档):

使用百度AI识别和tesseract 都十分精准,且速度都比较快。

相较而言,这里tesseract更有优势些,因为其不需要连网,库文件就在本地,百度AI实际需要网络传给百度再回调回来识别后的数据。
2、中文识别
源文件如下:

上面是随便从一本书上拍照的内容。使用百度AI识别结果如下:

再看下tesseract 自带的汉字库识别结果:
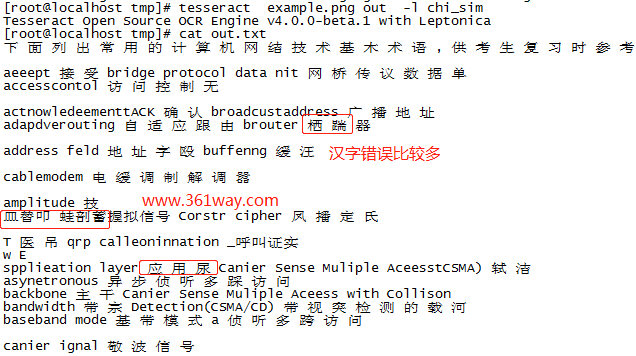
识别结果有点不正经吧,尿都识别出来了。而且汉字间都有空格的,基本是逐字识别的。
三、总结
baidu AI产品不做过多评论,商业应用产品,应用体验肯定没的说。而且其本身做搜索这些年,对汉字的单字、词句等经验积累比较多,其汉字库识别率,针对各种字体都有比较丰富的库。tesseract设计之初本就是针对英文的,而且英文识别比较容易,26个字母+数字+标占符号(没了吧,库小的不能再小了)。而汉字呢,常用字8000个不止吧,再加上一些生僻字,这个库文件大吧,后有各种不同的字体库,如宋体、黑体(虽然有些差别不大,但会有些许差别),这个库搞起来就有点麻烦了。但并不能就此说tesseract弱鸡(毕竟是市面上来说最牛X的开源文字识别软件了),其可以通过识别训练增加识别成功率,不过这个训练过程是比较痛苦的。
tesseract训练的文档可以参看如下两篇,后面有时间也会再搞下训练测试。
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/ocr-tesseract-baiduai/5693.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.