pandas小结(二)基础
pandas是Python中开源的,高性能的用于数据分析的库。其中包含了很多可用的数据结构及功能,各种结构支持相互转换,并且支持读取、保存数据。结合matplotlib库,可以将数据已图表的形式可视化,反映出数据的各项特征。pandas的一些基本使用方法,具体可以参数下图(后面会再单独说明):
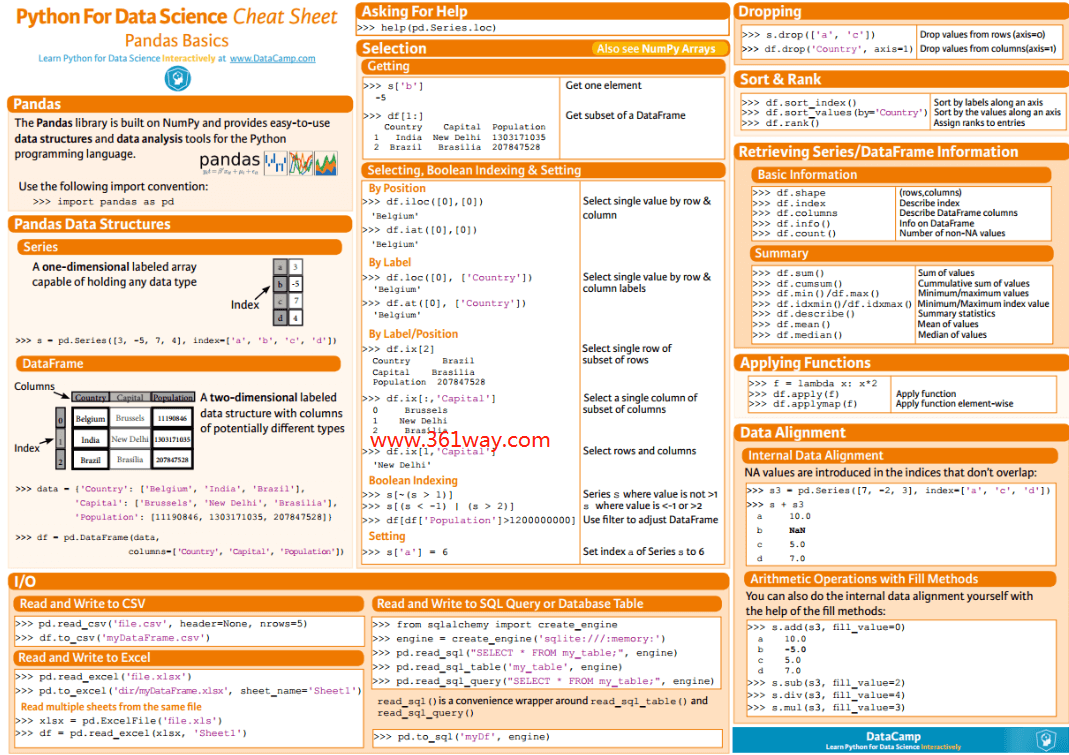
一、pandas的数据结构
pandas的安装比较简单,直接pip install pandas 就可以了。我们直接从数据结构开始。pandas分Seris 一维数据和DataFrame二维数据。
1.Seris
Seris是一维的,带索引的数组,支持多种数据类型。可以使用列表进行转换:
1import pandas as pd
2s = pd.Series([3, -5, 7, 4], index=['a', 'b', 'c', 'd'])
3print(s)
输出结果如下:
1a 3
2b -5
3c 7
4d 4
5dtype: int64
也可以重新指定索引:
1s.index = ['A', 'B', 'C', 'D']
2print(s)
2.DataFrame
一种二维的,类似于Excel表格的数据结构,可以为其指定列名、索引名。将字典结构转换为DataFrame:
1data = {
2 'Country': ['Belgium', 'India', 'Brazil'],
3 'Capital': ['Brussels', 'New Delhi', 'Brasília'],
4 'Population': [11190846, 1303171035, 207847528]
5}
6df = pd.DataFrame(data, columns=['Country', 'Capital', 'Population'])
7print(df)
8#执行后输出结果如下
9 Country Capital Population
100 Belgium Brussels 11190846
111 India New Delhi 1303171035
122 Brazil Brasília 207847528
二、查看DataFrame数据的基本信息
对已一个刚接触的数据集,最好的了解它的方式就是先通过一些简单的命令查看他的基本结构,比如有多少行、多少列,列名是什么,是否有索引等等。pandas提供了这样的一系列命令让我们能够轻松的进行查询。
1# 查看行列信息(几行,几列)
2print(df.shape)
3#查看列名及索引名
4print(df.columns)
5print(df.index)
6#查看DataFrame的描述信息
7print(df.info())
8#查看头尾几行
9print(df.head())
10print(df.tail())
df.info()显示的信息较全面,对索引、列、数据类型都做出了描述。df.head和df.tail默认只显示五行的数据。
三、DataFrame子集的选择
1、根据列名选择:
1selected_cols = ['Country', 'Capital']
2new_df = df[selected_cols]
3print(new_df)
4#执行结果如下
5 Country Capital
60 Belgium Brussels
71 India New Delhi
82 Brazil Brasília
2、根据标签选择
使用loc[]方法通过指定列名、索引名来获得相应的数据集。以我上面使用的df数据为例,取第3行的’Country’列的数据:
1print(df.loc[2, 'Country'])
2执行结果:
3Brazil
3、根据位置选择
使用iloc[]通过指定列名、索引名对应的索引位置(从0到n-1)获取数据(可以使用slice分片方式表示)。如果我想取前2行中最后2列的数据,应该这样表示:
1print(df.iloc[:2, -2:])
2#执行结果如下:
3Capital Population
40 Brussels 11190846
51 New Delhi 1303171035
4、布尔索引(Boolean Indexing)
也叫做布尔掩码(Boolean mask),是指先根据条件对DataFrame进行运算,生成一个值为True/False的DataFrame,再通过此DF与原DF进行匹配,得到符合条件的DF,不符合条件的显示为NaN:
1mask = df > 207847527
2print(df[mask].head())
3# 输出结果如下:
4 Country Capital Population
50 Belgium Brussels NaN
61 India New Delhi 1.303171e+09
72 Brazil Brasília 2.078475e+08
对于上面的一维Seris 也可以用,如下:
1mask = s > 3.5
2print(s[mask])
3#输出结果如下
4C 7
5D 4
6dtype: int64
关于布尔索引这部分,也可以对单列进行操作,我们再看个示例,先生成测试数据:
1import numpy as np
2import pandas as pd
3df = pd.DataFrame(np.random.randint(100, size=(5, 5)), columns = list("ABCDE"),
4 index = ["R" + str(i) for i in range(5)])
5print(df)
6#输出结果如下
7 A B C D E
8R0 28 98 64 94 67
9R1 39 69 59 39 75
10R2 4 95 41 34 28
11R3 68 92 99 63 55
12R4 12 99 0 7 92
指定单列进行判断:
1mask = df['A'] > 10
2print (mask)
3#输出结果
4R0 True
5R1 True
6R2 False
7R3 True
8R4 True
9Name: A, dtype: bool
对整个数据进行mask的结果如下:
1print(df[mask])
2# 输出结果
3 A B C D E
4R0 28 98 64 94 67
5R1 39 69 59 39 75
6R3 68 92 99 63 55
7R4 12 99 0 7 92
四、Broadcasting
通过将某一列的值刷成固定的值。例如对一些身高数据做转换时,添加一列’SEX’列,并统一将值更新为’MALE’:
1heights = [59.0, 65.2, 62.9, 65.4, 63.7]
2data = {
3 'height': heights, 'sex': 'Male',
4}
5df_heights = pd.DataFrame(data)
6print(df_heights)
7#执行结果如下:
8 height sex
90 59.0 Male
101 65.2 Male
112 62.9 Male
123 65.4 Male
134 63.7 Male
五、设置列名及索引名
如果需要重新指定列名或索引名,可直接通过df.columns(),df.index()指定。
1df_heights.columns = ['HEIGHT', 'SEX']
2df_heights.index = ['david', 'bob', 'lily', 'sara', 'tim']
3print(df_heights)
4# result
5 HEIGHT SEX
6david 59.0 Male
7bob 65.2 Male
8lily 62.9 Male
9sara 65.4 Male
10tim 63.7 Male
六、使用聚合函数
如果需要对数据进行一些统计,可使用聚合函数进行计算。
1、df.sum()
将所有值按列加到一起,字符串sum后会合并在一起:
1print(df_heights.sum())
2# result
3HEIGHT 316.2
4SEX MaleMaleMaleMaleMale
5dtype: object
2、df.cumsum()
统计累积加和值:
1print(df_heights.cumsum())
2# result
3 HEIGHT SEX
4david 59 Male
5bob 124.2 MaleMale
6lily 187.1 MaleMaleMale
7sara 252.5 MaleMaleMaleMale
8tim 316.2 MaleMaleMaleMaleMale
3、df.max() / df.min()
求最大/最小值
1print(df_heights.max())
2# result
3HEIGHT 65.4
4SEX Male
5dtype: object
6-------------------------------
7print(df_heights.min())
8# result
9HEIGHT 59
10SEX Male
11dtype: object
4、df.mean()
求平均数,数据类型为字符串的列会被自动过滤。
1print(df_heights.mean())
2# result
3HEIGHT 63.24
4dtype: float64
5、df.median()
求中位数
1print(df_heights.median())
2# result
3HEIGHT 63.7
4dtype: float64
6、df.describe()
获取DF的基本统计信息:
1print(df_heights.describe())
2# result
3 HEIGHT
4count 5.000000
5mean 63.240000
6std 2.589015
7min 59.000000
825% 62.900000
950% 63.700000
1075% 65.200000
11max 65.400000
七、从DataFrame中删除数据
1、通过指定行索引删除行数据
1df_heights.drop(['david', 'tim'])
2print(df_heights)
3# result
4 HEIGHT SEX
5david 59.0 Male
6bob 65.2 Male
7lily 62.9 Male
8sara 65.4 Male
9tim 63.7 Male
我们发现drop’david’, ‘tim’所在行后,再次打印df_height,之前删除的两行数据还在。说明drop()方法不会直接对原有的DF进行操作,如果需要改变原DF,需要使用inplace=’True’参数。
2、通过指定列值删除列数据(需指定axis=1)
1print(df_heights.drop('SEX', axis=1))
2# result
3HEIGHT
4david 177.0
5bob 195.6
6lily 188.7
7sara 196.2
8tim 191.1
八、排序与排名
1、根据索引值进行排序
1print(df_heights.sort_index())
2# result
3 HEIGHT SEX
4bob 65.2 Male
5david 59.0 Male
6lily 62.9 Male
7sara 65.4 Male
8tim 63.7 Male
2、根据值进行排序(需指定列名)
1print(df_heights.sort_values(by='HEIGHT'))
2# result
3 HEIGHT SEX
4david 59.0 Male
5lily 62.9 Male
6tim 63.7 Male
7bob 65.2 Male
8sara 65.4 Male
3、排名
根据列值进行排名,这点是和排序有区别的,具体看如下结果:
1print(df_heights.rank())
2# result
3 HEIGHT SEX
4david 1.0 3.0
5bob 4.0 3.0
6lily 2.0 3.0
7sara 5.0 3.0
8tim 3.0 3.0
九、使用lambda函数
对df_heights中的身高列进行转换(inch -> cm)
1df_heights = df_heights.apply(lambda height: height*3)
2print(df_heights)
3# result
4 HEIGHT SEX
5david 177.0 MaleMaleMale
6bob 195.6 MaleMaleMale
7lily 188.7 MaleMaleMale
8sara 196.2 MaleMaleMale
9tim 191.1 MaleMaleMale
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/pandas-base/6178.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.