Python bytearray() 函数
一、bytearray()用法
bytearray() 方法为python内置函数,其用于返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256。其语法如下:
1class bytearray([source[, encoding[, errors]]])
- 如果 source 为整数,则返回一个长度为 source 的初始化数组;
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
二、示例
1、source为字符串时
1>>> s = 'xyz'
2>>> b = bytearray(str(s),'utf8')
3>>> print b
4xyz
5>>> print b[1]
6121
7>>> print b[0]
8120
9>>> print b[2]
10122
11>>> b = bytearray(u'中国','utf8')
12>>> print b
13中国
14>>> len(b)
156
16>>> b[0]
17228
18>>> b[5]
19189
20>>> b = bytearray('中国','utf8')
21Traceback (most recent call last):
22 File "<stdin>", line 1, in <module>
23UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
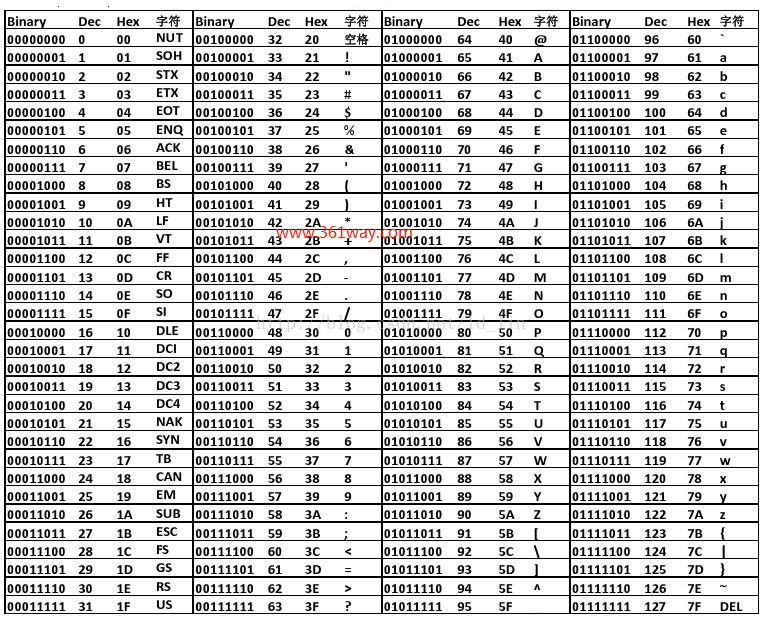
可以看出,我上面用xyz值时,经bytearray函数处理过后,返回的是字符的ASCII码值(标准ASCII码128位,加扩展位为256位,但这里取值和标准ASCII能对上,和扩展位是对应不上的)。可以看出在使用中文时,必须指定为unicode类型,不然会报超出ascii 128位的范围。ASCII码表对应如下(点击图片看大图):
2、source参数为整数时
1>>> b = bytearray(5)
2>>> print b
3>>> print len(b)
45
5>>> print b[0]
6>>> print b[1]
7>>> bytearray(5)
8bytearray(b'\x00\x00\x00\x00\x00')
其返回这个整数所指定长度的空字节数组。
3、source参数为object对象时
当source参数为实现了buffer接口的object对象时,那么将使用只读方式将字节读取到字节数组后返回;当source参数是一个可迭代对象,那么这个迭代对象的元素都必须符合0 <= x < 256,以便可以初始化到数组里。如下:
1>>> b = bytearray([1,2,3,4,5])
2>>> print len(b)
35
4>>> print b[1]
52
6>>> b = bytearray([1,2,3,4,5,256])
7Traceback (most recent call last):
8 File "<stdin>", line 1, in <module>
9ValueError: byte must be in range(0, 256)
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/python-bytearray/5776.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.