How to use probes in k8s
一、Kubernetes probes三种探针
k8s存在存活(Liveness)、就绪(Readiness)和启动(Startup)三种探针,根据k8s官方的描述如下:
- kubelet 使用存活探针(Liveness)来确定什么时候要
重启容器。 例如,存活探针可以探测到应用死锁(应用程序在运行,但是无法继续执行后面的步骤)情况。 重启这种状态下的容器有助于提高应用的可用性,即使其中存在缺陷。 - kubelet 使用就绪探针(Readiness)可以知道容器何时准备好接受请求流量,当一个 Pod 内的所有容器都就绪时,才能认为该 Pod 就绪。 这种信号的一个用途就是控制哪个 Pod 作为 Service 的后端。
若 Pod 尚未就绪,会被从 Service 的负载均衡器中剔除。 - kubelet 使用启动探针(Startup)来了解应用容器何时启动。 如果配置了这类探针,你就
可以控制容器在启动成功后再进行存活性和就绪态检查, 确保这些存活、就绪探针不会影响应用的启动。 启动探针可以用于对慢启动容器进行存活性检测,避免它们在启动运行之前就被杀掉。
二、Kubernetes probes探针四种检测方式
探针probes主要有四种方法来检查容器状态, 每个探针都必须准确定义为这四种机制中的一种:
exec:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。grpc:使用 gRPC 执行一个远程过程调用。 目标应该实现 gRPC健康检查。 如果响应的状态是 “SERVING”,则认为诊断成功。 gRPC 探针是一个 Alpha 特性,只有在你启用了 “GRPCContainerProbe” 特性门控时才能使用。httpGet:对容器的 IP 地址上指定端口和路径执行 HTTP GET 请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。tcpSocket:对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。 如果远程系统(容器)在打开连接后立即将其关闭,这算作是健康的。
三、Pod 调度状态及调度参数
pod的调度状态
K8s的pod调度时会有podstatus。Kubelet 管理以下 PodCondition:
PodScheduled:Pod 已经被调度到某节点;PodHasNetwork:Pod 被成功创建并且配置了网络;ContainersReady:Pod 中所有容器都已就绪;Initialized:所有的 Init 容器都已成功完成;Ready:Pod 可以为请求提供服务,并且应该被添加到对应服务的负载均衡池中。
pod调度参数
对于存活(Liveness)、就绪(Readiness)和启动(Startup)三种探针,您可以配置几个字段来控制探测的行为:
initialDelaySeconds:容器启动后经过这个时间(以秒为单位)后才可以调度探测。默认值为 0。periodSeconds:执行探测间的延迟时间(以秒为单位)。默认值为10。这个值必须大于timeoutSeconds。timeoutSeconds:不活跃状态维持了这个时间(以秒为单位)后,探测超时,容器被认为已失败。默认值为1。这个值必须小于periodSeconds。successThreshold:探测在失败后必须报告成功的次数,才会重置容器状态为成功。对于存活度探测,这个值必须是1。默认值为1。failureThreshold:这个探测允许失败的次数。默认值为 3。在指定的尝试后:- 对于存活度探测,容器被重启
- 对于就绪度探测,pod 标记为
Unready - 对于启动探测,容器会终止,并取决于 pod 的
restartPolicy
配置示例
配置示例如下:
1apiVersion: v1
2kind: Pod
3metadata:
4 labels:
5 test: health-check
6 name: my-application
7...
8spec:
9 containers:
10 - name: goproxy-app
11 args:
12 image: k8s.gcr.io/goproxy:0.1
13 livenessProbe:
14 httpGet:
15 scheme: HTTPS
16 path: /healthz
17 port: 8080
18 httpHeaders:
19 - name: X-Custom-Header
20 value: Awesome
21 startupProbe:
22 httpGet:
23 path: /healthz
24 port: 8080
25 failureThreshold: 30
26 periodSeconds: 10
27...
以上是 redhat openshift上给出的示例。在具体执行过程中,可以通过运行kubectl get pod 查看pod状态。
四、一个示例
这里并没有使用k8s官方网站的示例,也没有使用redhat openshit上的示例。这里使用的是github上的一个示例on GitHub。
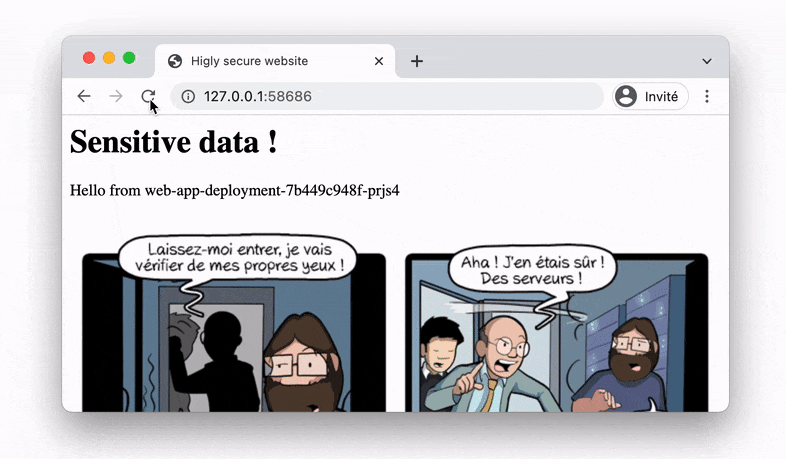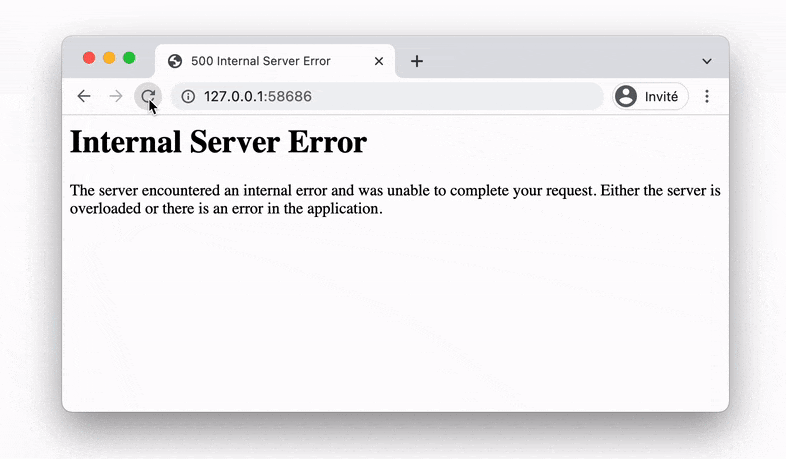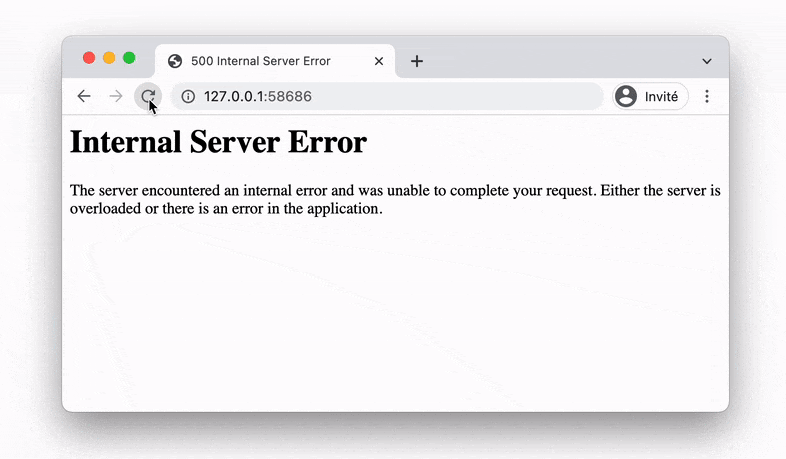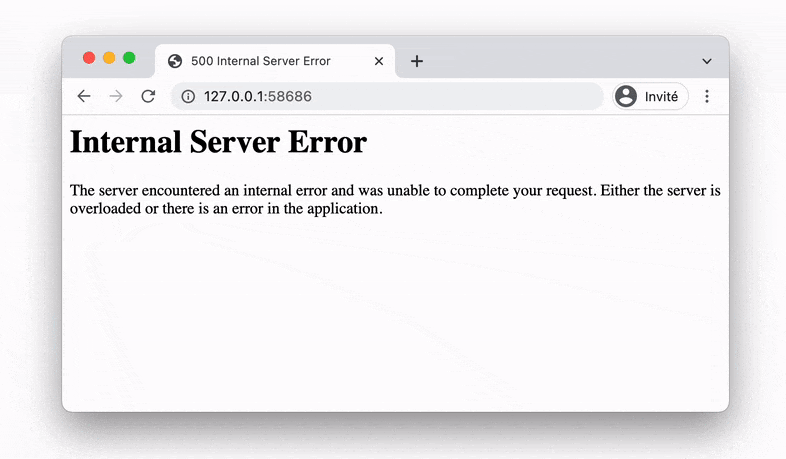
程序内容比较简单,是通过flask程序生成10以内的随机数,如果数字刚好为7,刚健康检查函数则认为探测到了判断为假的结果,在http_get探针累计到三次以后,pod就会发生重启,页面会返回500的内部错误,如果是其他数则返回一张图片。
1# app.py
2from flask import Flask, render_template
3from random import randrange
4from os import environ as env
5
6app = Flask(__name__)
7healthy = True
8
9
10def update_health():
11 global healthy
12 if randrange(10) == 7:
13 healthy = False
14 return healthy
15
16
17@app.route("/")
18def hello_world():
19 if update_health():
20 return render_template(
21 "index.html", pod_name=env.get("POD_NAME", "somewhere")
22 )
23
24
25@app.route("/healthz")
26def healthz():
27 if update_health():
28 return "OK"
这里 healthy 会有10%的概率为flase,我们可以将该代码在Kubernetes cluster, Minikube or K3s上运行测试。
1$ kubectl apply -f kubernetes/deployment.yaml
2$ kubectl apply -f kubernetes/service.yaml
当然这里运行后,多次刷新后,pod能否重启也取决于使用的探针的类型,仅有在使用存数探针的情况下,程序才会重启。
参考页面:
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/k8s-probes/6932.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.