Pandas中lambda函数的应用
在使用pandas的过程中,我们可以结合lambda函数很方便的进行各种数据处理操作。而lambda在pandas就又经常和df.assign、df.apply两个函数组合使用,df.assign经常用于列的修改和新增,apply经常作用于一维向量上,其既可作用于行,也可以作用于列,又可作用于元素。lambda单独使用的示例如下:
1lambda:输入是传入到参数列表x的值,输出是根据表达式(expression)计算得到的值。
2比如:lambda x, y: xy #函数输入是x和y,输出是它们的积xy
3lambda x :x[-2:] #x是字符串时,输出字符串的后两位
4lambda x :func #输入 x,通过函数计算后返回结果
5lambda x: ‘%.2f’ % x # 对结果保留两位小数
lambda与pandas组合使用,只保留某列字符的最后两位内容的操作如下:
1df[‘time’]=df[‘time’].apply(lambda x :x[-2:])
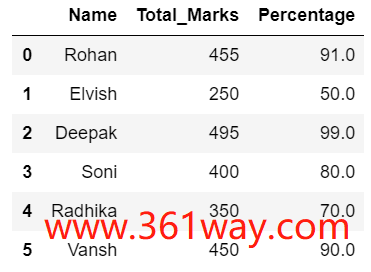
1、使用lambda增加Dataframe一列
df.assign是进行创建修改列操作的函数。
1# importing pandas library
2import pandas as pd
3# creating and initializing a list
4values= [['Rohan',455],['Elvish',250],['Deepak',495],
5 ['Soni',400],['Radhika',350],['Vansh',450]]
6# creating a pandas dataframe
7df = pd.DataFrame(values,columns=['Name','Total_Marks'])
8# Applying lambda function to find
9# percentage of 'Total_Marks' column
10# using df.assign()
11df = df.assign(Percentage = lambda x: (x['Total_Marks'] /500 * 100))
12# displaying the data frame
13df
2、使用lambda进行多列操作
1# importing pandas library
2import pandas as pd
3# creating and initializing a nested list
4values_list = [[15, 2.5, 100], [20, 4.5, 50], [25, 5.2, 80],
5 [45, 5.8, 48], [40, 6.3, 70], [41, 6.4, 90],
6 [51, 2.3, 111]]
7# creating a pandas dataframe
8df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'])
9# Applying lambda function to find
10# the product of 3 columns using
11# df.assign()
12df = df.assign(Product=lambda x: (x['Field_1'] * x['Field_2'] * x['Field_3']))
13# printing dataframe
14df
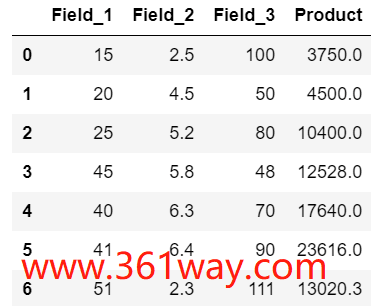
上面最后一列的结果是前面三列结果的乘积。
3、单行apply操作
通过符合条件的单行进行平方操作。这里使用了lambda和apply函数的结果,axis=1代表对行进行操作,默认是对列进行操作。
1# importing pandas and numpy libraries
2import pandas as pd
3import numpy as np
4# creating and initializing a nested list
5values_list = [[15, 2.5, 100], [20, 4.5, 50], [25, 5.2, 80],
6 [45, 5.8, 48], [40, 6.3, 70], [41, 6.4, 90],
7 [51, 2.3, 111]]
8# creating a pandas dataframe
9df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'],
10 index=['a', 'b', 'c', 'd', 'e', 'f', 'g'])
11# Apply function numpy.square() to square
12# the values of one row only i.e. row
13# with index name 'd'
14df = df.apply(lambda x: np.square(x) if x.name == 'd' else x, axis=1)
15# printing dataframe
16df
执行结果如下:
1Field_1 Field_2 Field_3
2----------------------------------------
3a 15.0 2.50 100.0
4b 20.0 4.50 50.0
5c 25.0 5.20 80.0
6d 2025.0 33.64 2304.0
7e 40.0 6.30 70.0
8f 41.0 6.40 90.0
9g 51.0 2.30 111.0
4、lambda多行操作示例
可以通过循环,对多行记录进行操作,具体如下:
1# importing pandas and numpylibraries
2import pandas as pd
3import numpy as np
4# creating and initializing a nested list
5values_list = [[1.5, 2.5, 10.0], [2.0, 4.5, 5.0], [2.5, 5.2, 8.0],
6 [4.5, 5.8, 4.8], [4.0, 6.3, 70], [4.1, 6.4, 9.0],
7 [5.1, 2.3, 11.1]]
8# creating a pandas dataframe
9df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'],
10 index=['a', 'b', 'c', 'd', 'e', 'f', 'g'])
11# Apply function numpy.square() to square
12# the values of 2 rows only i.e. with row
13# index name 'b' and 'f' only
14df = df.apply(lambda x: np.square(x) if x.name in ['b', 'f'] else x, axis=1)
15# Applying lambda function to find product of 3 columns
16# i.e 'Field_1', 'Field_2' and 'Field_3'
17df = df.assign(Product=lambda x: (x['Field_1'] * x['Field_2'] * x['Field_3']))
18# printing dataframe
19df
执行结果如下:
1Field_1 Field_2 Field_3 Product
2-----------------------------------------
3a 1.50 2.50 10.0 37.5000
4b 4.00 20.25 25.0 2025.0000
5c 2.50 5.20 8.0 104.0000
6d 4.50 5.80 4.8 125.2800
7e 4.00 6.30 70.0 1764.0000
8f 16.81 40.96 81.0 55771.5456
9g 5.10 2.30 11.1 130.2030
5、同时进行多行多列的操作
这时候可以通过df.apply和df.assign函数同时作用多行和列的值:
1# importing pandas and numpylibraries
2import pandas as pd
3import numpy as np
4# creating and initializing a nested list
5values_list = [[1.5, 2.5, 10.0], [2.0, 4.5, 5.0], [2.5, 5.2, 8.0],
6 [4.5, 5.8, 4.8], [4.0, 6.3, 70], [4.1, 6.4, 9.0],
7 [5.1, 2.3, 11.1]]
8# creating a pandas dataframe
9df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'],
10 index=['a', 'b', 'c', 'd', 'e', 'f', 'g'])
11# Apply function numpy.square() to square
12# the values of 2 rows only i.e. with row
13# index name 'b' and 'f' only
14df = df.apply(lambda x: np.square(x) if x.name in ['b', 'f'] else x, axis=1)
15# Applying lambda function to find product of 3 columns
16# i.e 'Field_1', 'Field_2' and 'Field_3'
17df = df.assign(Product=lambda x: (x['Field_1'] * x['Field_2'] * x['Field_3']))
18# printing dataframe
19df
执行结果如下:
1Field_1 Field_2 Field_3 Product
2-------------------------------------------
3a 1.50 2.50 10.0 37.5000
4b 4.00 20.25 25.0 2025.0000
5c 2.50 5.20 8.0 104.0000
6d 4.50 5.80 4.8 125.2800
7e 4.00 6.30 70.0 1764.0000
8f 16.81 40.96 81.0 55771.5456
9g 5.10 2.30 11.1 130.2030
6、apply函数操作
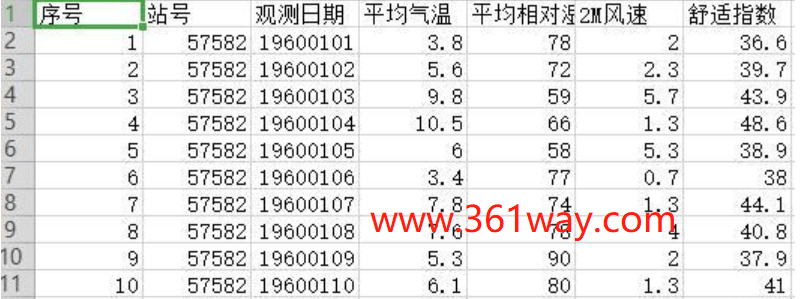
最后再列一个通过风速、气温、相对湿度计算人体舒适度指数的示例,如下:
1import pandas as pd
2import numpy as np
3import math
4path='D:\\data\\57582.csv' #文件路径
5data=pd.read_csv(path,index_col=0,encoding='gbk') #读取数据有中文时用gbk解码
6#定义舒适指数公式函数,结果保留1位小数
7def get_CHB(T,RH,S):
8 return round(1.8*T-0.55*(1.8*T-26)*(1-RH/100)-3.2*math.sqrt(S)+32,1)
9#增加一列CHB并计算数据后赋值
10data['舒适指数']=data.apply(lambda x:get_CHB(x['平均气温'],x['平均相对湿度'],x['2M风速']),axis=1)
11#打印结果
12print(data)
13#保存结果
14data.to_csv('D:\\CHB.csv',encoding='gbk')
代码中使用了apply和lambda的组合,传入的参数x为整个data数据,在函数中引入的参数则是x[‘平均气温’],x[‘平均相对湿度’],x[‘2M风速’],与自定义的函数get_CHB对应。最后需使用axis=1来指定是对列进行运算。计算结果是:
捐赠本站(Donate)
 如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))
- Author: shisekong
- Link: https://blog.361way.com/pandas-lambda/6587.html
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.